Pourquoi les puces et la HBM sont devenues les premiers hotspots
En analysant la vague actuelle de l’IA, les premiers secteurs à attirer une valorisation concentrée sur les marchés financiers se sont presque tous focalisés sur les puces et la mémoire. La logique est évidente : l’itération rapide des grands modèles dépend de capacités de formation à grande échelle, et la contrainte la plus directe sur la capacité d’entraînement est l’offre de puissance de calcul haut de gamme. Plus on acquiert de GPU, plus l’opportunité de former des modèles plus grands, de fournir des services cloud performants et de construire des barrières d’écosystème profondes s’accroît.
Cependant, à mesure que la puissance de calcul des puces individuelles augmente, de nouveaux goulets d’étranglement apparaissent rapidement. Les systèmes IA doivent non seulement “calculer vite”, mais aussi être “alimentés suffisamment”. Cela a rapidement renforcé l’importance stratégique de la mémoire à large bande passante (HBM). Pour l’entraînement de grands modèles et l’inférence à haute densité, la bande passante mémoire n’est plus un facteur secondaire — elle devient une variable centrale impactant directement le débit, la latence et l’efficacité énergétique.
Des rapports publics récents confirment cette logique. Selon Reuters, la direction du groupe SK a indiqué que la pénurie mondiale de wafers pourrait durer jusqu’en 2030, et SK Hynix prévoit que la demande de HBM devrait dépasser l’offre pendant plusieurs années. Cela montre que l’attention portée par le marché aux puces et à la HBM ne relève pas seulement du sentiment : l’IA restructure fondamentalement la dynamique de l’offre et de la demande sur les semi-conducteurs haut de gamme.
Trois raisons principales expliquent pourquoi les puces et la HBM sont devenues les premiers hotspots :
- Le goulet d’étranglement est le plus évident : lors de la phase de formation, l’écart de puissance de calcul est le plus facile à quantifier et le plus identifiable par l’industrie et les marchés financiers.
- L’expansion de l’offre est la plus lente : la logique haut de gamme, le packaging avancé et la HBM sont tous des segments à barrières élevées, avec des cycles d’expansion longs, des exigences de certification strictes et des difficultés de substitution importantes.
- La transmission des prix est la plus directe : lorsque la pénurie d’offre persiste, les changements de commandes, de prix et de profits se reflètent plus rapidement dans la performance des entreprises.
Ainsi, les puces, la HBM et le packaging avancé ont continué à s’intensifier récemment, en phase avec les fondamentaux de l’industrie et les préférences du marché.
Pourquoi l’infrastructure IA bascule de l’entraînement vers l’inférence
Bien que les puces et la HBM restent essentielles, le centre de gravité de l’infrastructure IA a déjà commencé à évoluer. Auparavant, l’industrie se concentrait sur l’entraînement des modèles ; désormais, davantage de ressources sont consacrées au déploiement de l’inférence et aux opérations en production.
La raison est claire : l’entraînement fixe la limite supérieure des capacités du modèle, tandis que l’inférence détermine l’échelle de la commercialisation. L’entraînement est une activité à fort investissement, réservée à quelques leaders, alors que l’inférence intervient à chaque appel utilisateur réel. Des scénarios comme la recherche, la productivité bureautique, le support client, la publicité, la génération de code, la génération vidéo, la base de connaissances d’entreprise et l’automatisation Agent dépendent tous de requêtes d’inférence continues.
Selon le rapport Enterprise Application Strategy 2026 de F5, 78 % des entreprises exécutent déjà l’inférence IA comme capacité opérationnelle centrale, et 77 % estiment que l’inférence — et non l’entraînement — est le principal scénario d’activité IA. Ce chiffre envoie un signal fort : l’IA passe du laboratoire aux systèmes de production, et la demande évolue de la “compétition de capacité de modèle” vers la “compétition d’efficacité opérationnelle”.
Quand l’IA pénètre les processus métier réels, les préoccupations clés des entreprises basculent du nombre de paramètres du modèle vers des indicateurs opérationnels tels que :
- La latence est-elle stable ?
- Les coûts sont-ils maîtrisés ?
- Peut-on router et basculer entre plusieurs modèles ?
- Les données sont-elles sécurisées ?
- Les résultats sont-ils auditables ?
- Le système peut-il s’intégrer aux plateformes métier existantes ?
Cela signifie que l’infrastructure IA évolue des clusters d’entraînement uniques vers des systèmes d’exploitation d’inférence plus complexes, incluant :
- Plateformes de services de modèles
- Frameworks d’accélération d’inférence
- Routage et planification multi-modèles
- Recherche vectorielle et gestion du contexte
- Systèmes d’orchestration Agent
- Audit de sécurité et contrôle d’accès
Ce basculement se retrouve aussi dans la stratégie des fournisseurs hardware. Dans sa publication 2026, Google Cloud a mis en avant les produits TPU optimisés pour l’inférence, soulignant la faible latence, le contexte long et la concurrence Agent à grande échelle. L’architecture matérielle elle-même évolue du “training-first” vers l’“inference-first”.
Pourquoi le véritable goulet d’étranglement s’étend aux data centers et à l’énergie
Si la question principale de l’étape précédente était “Y a-t-il des GPU disponibles ?”, la question urgente désormais est “Une fois les GPU acquis, peut-on les déployer de façon fiable ?”
Cela marque la deuxième étape de l’infrastructure IA. Les GPU restent des actifs centraux, mais ils ne deviennent productifs que s’ils sont associés à des data centers, à l’énergie, au refroidissement, au réseau, au switching et aux systèmes d’exploitation. Autrement dit, le goulet d’étranglement de l’industrie IA est passé du hardware individuel à la capacité système complète.
Plusieurs évolutions publiques récentes illustrent cette tendance :
- Les principaux acteurs technologiques nord-américains continueront d’augmenter leurs dépenses d’investissement IA en 2026, en investissant non seulement dans les puces mais aussi dans les campus de data centers, l’architecture réseau et l’expansion de l’infrastructure.
- Les prévisions publiques du secteur énergétique américain montrent que la consommation atteindra de nouveaux sommets en 2026 et 2027, avec les data centers et l’IA comme moteurs principaux.
- Plusieurs projets de data centers IA hyperscale se concentrent sur des centaines de mégawatts d’alimentation, des baux longue durée et le développement de campus, ce qui indique que l’industrie se focalise sur “comment soutenir la puissance de calcul”.
Cela signifie que l’industrie IA ressemble de plus en plus à un système industriel lourd, et non à une simple expansion asset-light de l’ère internet. La variable clé pour l’expansion future passe de “peut-on concevoir des puces plus puissantes” à “peut-on rapidement sécuriser l’énergie, le foncier, le refroidissement et les ressources réseau”.
D’un point de vue industriel, cette transformation entraîne au moins quatre conséquences :
- Les data centers passent du statut d’actifs IT à celui d’actifs stratégiques : les workloads IA à haute densité exigent de nouveaux standards pour les installations, la distribution électrique et le refroidissement.
- L’énergie devient la nouvelle ressource rare : dans certaines régions, les GPU ne sont plus la ressource la plus difficile à obtenir — un accès stable et long terme à l’énergie l’est davantage.
- L’importance du refroidissement et du refroidissement liquide monte en flèche : à mesure que la densité de puissance des clusters IA augmente, les méthodes de refroidissement traditionnelles deviennent insuffisantes.
- Les interconnexions à haute vitesse déterminent l’efficacité des clusters : à mesure que la puissance de calcul s’accroît, la performance système dépend moins des cartes individuelles que de l’architecture réseau et switching.
Ainsi, la compétition centrale dans l’infrastructure IA ne porte plus sur des percées ponctuelles, mais sur la collaboration au niveau système.
Les cinq axes de croissance les plus rapides des 2–3 prochaines années
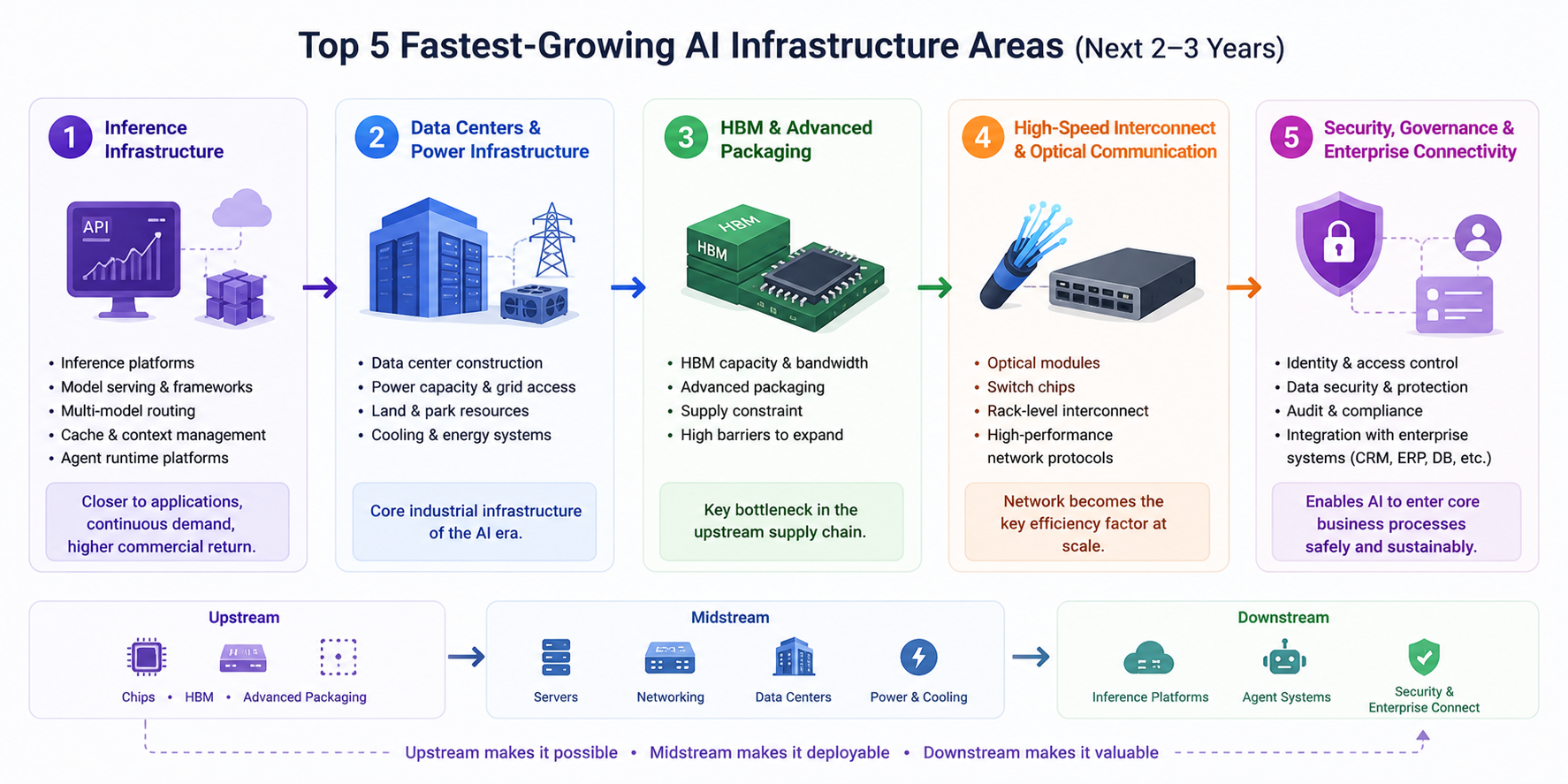
Sur la base des informations publiques récentes et des évolutions de la chaîne industrielle, les axes de croissance les plus rapides de l’infrastructure IA pour les 2–3 prochaines années se déclinent en cinq catégories :
- Infrastructure d’inférence : c’est la catégorie la plus digne d’une attention continue. À mesure que les applications IA passent en production, les plateformes d’inférence, frameworks de service de modèles, routage multi-modèles, gestion du cache et du contexte, et plateformes d’exploitation Agent vont croître rapidement. Comparée à l’entraînement, la demande d’inférence est plus distribuée, soutenue et proche du retour commercial.
- Data centers et soutien énergétique : les data centers deviennent le cœur de l’infrastructure industrielle à l’ère IA. Ceux qui sécurisent plus vite les quotas d’énergie, le foncier, les conditions de campus et les systèmes de refroidissement seront mieux positionnés pour la prochaine vague d’expansion de la puissance de calcul. Dans les années à venir, la vitesse de construction des data centers influencera profondément le rythme de croissance de l’industrie IA.
- HBM et packaging avancé : cela reste l’un des principaux goulets d’étranglement de la chaîne d’approvisionnement amont. À mesure que la performance des puces augmente, les exigences en capacité HBM, bande passante et technologie de packaging s’intensifient, tandis que la capacité associée est difficile à augmenter rapidement — ce qui laisse présager une forte prospérité durable.
- Interconnexions à haute vitesse et communications optiques : à mesure que les clusters IA s’agrandissent, le réseau devient la variable clé de l’efficacité globale. Les modules optiques, les puces de switching, les interconnexions rack-level et des protocoles réseau plus efficaces deviendront des capacités fondamentales pour l’entraînement et l’inférence.
- Gouvernance de la sécurité et connectivité d’entreprise : cet axe est moins visible à court terme que les puces, mais sa valeur à long terme est considérable. Une fois l’IA d’entreprise intégrée au CRM, ERP, bases de données, dépôts de code et systèmes de connaissances, le contrôle d’accès, l’audit, la protection des données sensibles, le suivi des résultats et la gouvernance de conformité deviendront essentiels. Cette couche détermine si l’IA peut réellement intégrer les processus métier centraux.
Le chemin de transmission peut se résumer en une ligne principale plus claire :
- Amont : puces, HBM, packaging avancé
- Intermédiaire : serveurs, réseaux de switching, data centers, énergie et refroidissement
- Aval : plateformes d’inférence, systèmes Agent, gouvernance de sécurité et intégration d’entreprise
L’amont détermine “peut-on construire”, l’intermédiaire “peut-on déployer”, et l’aval “peut-on utiliser et continuer à créer de la valeur”.
Conclusion : la compétition IA entre dans l’ère du génie des systèmes
Ces dernières années, le marché a d’abord recherché les puces et la HBM car ces secteurs étaient les plus rares et offraient la dynamique offre-demande la plus visible. Mais à mesure que l’IA passe de la course à l’entraînement au déploiement de l’inférence, la logique industrielle change fondamentalement. Désormais, le véritable facteur de croissance n’est plus seulement la performance des puces individuelles, mais la capacité de l’ensemble de l’infrastructure à fonctionner de manière cohérente.
Un cadre plus structuré pour comprendre l’état actuel de l’infrastructure IA :
- L’entraînement fixe la limite supérieure des capacités
- L’inférence détermine l’échelle de la commercialisation
- Les data centers et l’énergie dictent la vitesse d’expansion
- La gouvernance de sécurité détermine la profondeur de l’adoption en entreprise
Cela signifie que la prochaine vague d’opportunités sur l’infrastructure IA ne se limitera pas aux puces, mais s’étendra à “l’infrastructure d’inférence + data centers + systèmes énergétiques + interconnexions à haute vitesse + plateformes de gouvernance d’entreprise”.
À long terme, l’IA évolue d’une industrie de compétition de modèles vers une industrie de génie des systèmes. Ceux qui parviendront à créer des synergies entre puissance de calcul, réseaux, énergie et plateformes opérationnelles seront les mieux placés pour mener l’expansion du secteur dans les 2–3 prochaines années.
Rappel de risque : cet article ne constitue pas un conseil en investissement et est fourni à titre informatif uniquement. Veuillez investir avec prudence.








