À mesure que les applications blockchain gagnent en ampleur, les données on-chain deviennent une ressource fondamentale pour la DeFi, l'analyse on-chain, les Agents IA, et les applications multi-chaînes. Or, les données brutes de la blockchain se présentent généralement sous forme de blocs, de transactions et de journaux d'événements, ce qui oblige les développeurs à passer par des pipelines complexes d'extraction et de traitement avant de pouvoir les exploiter. L'accès efficace aux données on-chain constitue donc un enjeu majeur pour le développement de l'infrastructure Web3.
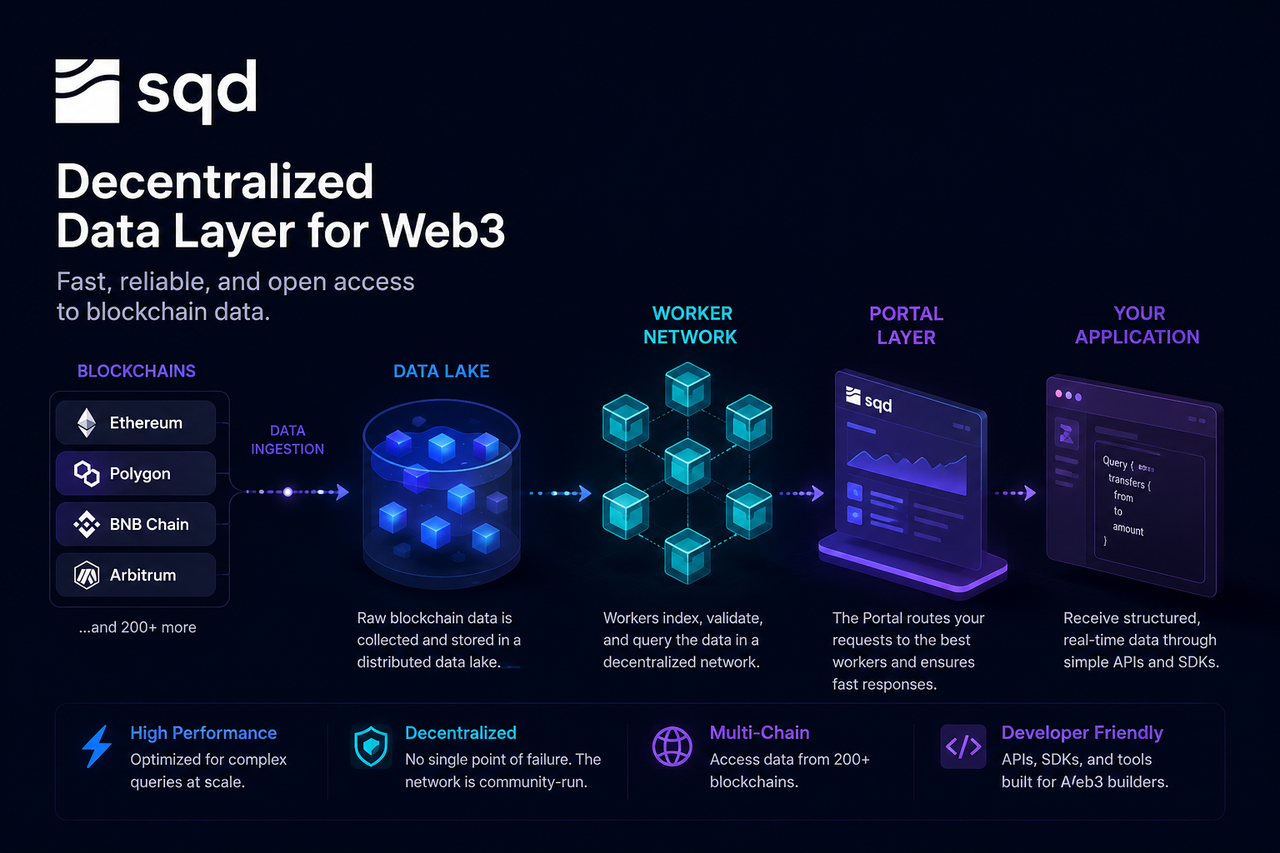
Subsquid (SQD) se présente comme un réseau de données décentralisé conçu pour résoudre ce problème. Contrairement aux nœuds RPC classiques qui lisent directement l'état de la blockchain, SQD propose une architecture de service de données articulée autour d'un lac de données, de nœuds de travail et d'une couche d'interrogation Portal, permettant aux développeurs d'accéder à des données on-chain structurées et indexées via une interface unique.
Qu'est-ce qu'une requête de données SQD ?
Une requête de données SQD est le processus par lequel les développeurs récupèrent des données on-chain via le réseau SQD. Au lieu d'interroger directement les nœuds de la blockchain, les requêtes SQD renvoient des données déjà prétraitées et indexées, offrant ainsi des réponses rapides à des demandes complexes.
Par exemple, un tableau de bord DeFi peut avoir besoin d'agréger les volumes d'échange des derniers mois, un Agent IA doit lire les variations d'actifs sur plusieurs adresses, et une plateforme d'analyse peut vouloir interroger l'historique complet des événements d'un contrat intelligent spécifique. Tous ces cas sont des scénarios typiques de requêtes de données.
L'idée maîtresse de SQD est de décharger le lourd traitement des données en amont, afin que les applications puissent accéder directement à des données structurées sans avoir à gérer elles-mêmes d'énormes volumes de données brutes.
Le point de départ d'une requête se situe en réalité avant même que le développeur n'envoie sa demande.
Alors que les réseaux blockchain génèrent continuellement de nouveaux blocs, le réseau SQD capture les données brutes — blocs, transactions, événements de journaux et changements d'état des contrats intelligents — en temps réel via son système de collecte. Ces données sont ensuite standardisées pour un traitement et un stockage ultérieurs.
Comme SQD prend en charge plusieurs blockchains, sa couche de collecte doit synchroniser en permanence les flux de données provenant de différents écosystèmes tout en garantissant l'intégrité et la cohérence des données. Après standardisation, les données sont écrites dans la couche de stockage du réseau.
Le lac de données est l'infrastructure de stockage centrale du réseau SQD.
Contrairement aux bases de données traditionnelles conçues pour les données structurées, un lac de données peut gérer de grands volumes de données brutes et semi-structurées. L'historique de la blockchain, les données de transaction, les journaux d'événements et les instantanés d'état y sont tous conservés.
L'avantage d'un lac de données est qu'il préserve un historique complet tout en permettant un traitement et une analyse aval flexibles. Pour les applications qui doivent retracer des millions de transactions, cette méthode de stockage est bien plus efficace que d'interroger directement les nœuds de la blockchain.
Le lac de données agit comme la mémoire à long terme du réseau SQD, fournissant les données nécessaires à l'indexation et aux requêtes ultérieures.
Les nœuds de travail constituent la couche d'exécution du réseau SQD.
Lorsque les données entrent dans le réseau, les nœuds de travail les indexent, les classifient et les optimisent pour une récupération rapide. L'indexation revient à créer une table des matières pour une immense encyclopédie : inutile de tout parcourir à chaque requête.
Outre la création d'index, les nœuds de travail exécutent les tâches de requête. Quand un développeur demande des données spécifiques, un nœud de travail localise rapidement les enregistrements pertinents via l'index, puis filtre, agrège et calcule les résultats.
Grâce au parallélisme de plusieurs nœuds de travail, le réseau peut gérer de nombreuses requêtes simultanément, améliorant ainsi les performances globales et l'évolutivité.
Portal est le point d'entrée unifié pour accéder au réseau SQD.
Les développeurs envoient généralement leurs requêtes via une API ou un SDK, sans se connecter directement aux nœuds sous-jacents. Lorsqu'une demande parvient à Portal, le système analyse la requête et détermine quels nœuds de travail sont les mieux adaptés pour la traiter.
Portal agit comme un équilibreur de charge sur Internet. Les développeurs interagissent avec une interface unique, tandis que l'ordonnancement complexe des ressources et la sélection des nœuds se font automatiquement en arrière-plan.
Cette conception simplifie le développement et améliore l'efficacité globale des ressources du réseau.
Une fois le traitement terminé, les nœuds de travail renvoient les résultats à la couche Portal.
Portal formate les résultats selon les besoins et transmet les données finales à l'application. Les développeurs reçoivent des données déjà structurées — par exemple, des objets JSON ou des résultats d'analyse — prêtes à être utilisées pour l'affichage frontal, la logique métier ou l'inférence IA.
L'ensemble du processus est généralement transparent pour l'utilisateur final. Il voit simplement la page se charger ou les résultats d'analyse apparaître, alors qu'en arrière-plan, plusieurs étapes — de la collecte des données à l'exécution des requêtes — ont déjà eu lieu.
Outre les requêtes historiques, de nombreuses applications ont besoin d'informations on-chain en temps réel.
Par exemple, les systèmes de surveillance on-chain doivent détecter les transactions anormales, les stratégies automatisées doivent écouter les événements des contrats intelligents, et les Agents IA doivent rester informés des dernières conditions du marché. Ces scénarios exigent que les données soient disponibles dès la production d'un nouveau bloc.
Hotblocks est la couche de données en temps réel fournie par SQD, spécialement conçue pour les nouveaux blocs et les événements en direct. Par rapport aux données historiques du lac de données, Hotblocks mise sur une faible latence et des réponses rapides, permettant aux développeurs de construire des applications en temps réel.
Les deux méthodes permettent d'accéder aux données on-chain, mais la logique sous-jacente est très différente.
Les nœuds RPC traditionnels reviennent à interroger directement une base de données blockchain. Chaque requête doit rechercher les données correspondantes dans l'état on-chain ou les enregistrements historiques. Plus le périmètre de la requête s'élargit, plus la pression sur les performances et les coûts augmente.
SQD, en revanche, utilise une architecture pré-indexée. Les données sont déjà organisées et indexées dès leur entrée dans le réseau, de sorte que les requêtes n'ont pas besoin de reparcourir tout l'historique. Pour les analyses complexes, l'agrégation de données multi-chaînes et les statistiques historiques à long terme, SQD offre généralement une efficacité bien supérieure.
| Dimension |
SQD |
RPC traditionnel |
| Source de données |
Données pré-indexées |
Lectures on-chain en temps réel |
| Efficacité des requêtes |
Élevée |
Moyenne |
| Analyse des données historiques |
Avantage significatif |
Plus complexe |
| Prise en charge multi-chaînes |
Forte |
Dépend de multiples nœuds |
| Coût d'infrastructure |
Plus faible |
Plus élevé |
| Lecture d'état en temps réel |
Prise en charge |
Prise en charge |
Les Agents IA deviennent une application clé dans l'infrastructure Web3, et l'accès aux données est fondamental pour leur fonctionnement.
Si un Agent IA doit analyser le comportement d'un portefeuille, suivre l'état des protocoles ou exécuter des actions on-chain, il doit obtenir en continu des données précises et structurées. Les requêtes RPC traditionnelles peuvent fournir des données brutes, mais elles nécessitent généralement un traitement et une transformation supplémentaires.
L'interface de données unifiée fournie par SQD réduit la complexité pour les Agents IA de récupérer des informations on-chain. Grâce à des résultats de requête standardisés, les systèmes d'IA peuvent consacrer davantage de puissance de calcul à l'analyse et à la prise de décision plutôt qu'à la manipulation des données.
À mesure que l'IA et le Web3 continuent de converger, l'importance des couches de données décentralisées ne fera que croître.
Résumé
Une requête de données SQD n'est pas une simple lecture de données : c'est un flux de travail complet impliquant la couche de collecte, le lac de données, les nœuds de travail et la couche Portal, agissant de concert. Les données brutes de la blockchain sont d'abord collectées et stockées, puis indexées et optimisées, et enfin fournies aux développeurs via une interface unique.
Ce modèle de traitement distribué et pré-indexé permet à SQD d'offrir une efficacité élevée pour les requêtes complexes, l'analyse multi-chaînes et l'accès aux données en temps réel. Alors que la DeFi, les plateformes d'analyse on-chain et les Agents IA exigent toujours plus de données, l'architecture de couche de données représentée par SQD devient un élément essentiel de l'infrastructure Web3.
FAQ
Quelle est la différence entre une requête de données SQD et une requête API classique ?
Une API classique est généralement maintenue par un fournisseur centralisé, tandis qu'une requête SQD s'exécute sur un réseau de données décentralisé. Les données SQD proviennent de systèmes de collecte et d'indexation on-chain, offrant un accès plus ouvert et vérifiable.
Pourquoi la vitesse des requêtes SQD est-elle plus rapide que celle de certaines requêtes RPC ?
SQD effectue l'indexation et l'organisation à l'avance, de sorte que les requêtes n'ont pas besoin de reparcourir de grandes quantités d'historique de blocs. Pour les tâches d'analyse complexes et de données historiques, SQD est généralement beaucoup plus rapide.
Quel rôle les nœuds de travail jouent-ils dans le processus de requête ?
Les nœuds de travail gèrent l'indexation, le filtrage, l'agrégation et le calcul. Lorsque Portal reçoit une demande de requête, les nœuds de travail concernés effectuent le traitement réel des données.
Quelle est la différence entre un lac de données et une base de données ?
Une base de données stocke généralement des données structurées, tandis qu'un lac de données peut stocker d'énormes volumes de données brutes et semi-structurées. SQD utilise un lac de données pour stocker l'historique complet on-chain, prenant en charge des requêtes et des analyses flexibles.
Hotblocks peut-il remplacer les requêtes de données historiques ?
Non. Hotblocks est conçu pour l'accès aux données en temps réel ; les requêtes historiques reposent toujours sur le lac de données et le système d'indexation. Ensemble, ils forment la capacité complète de service de données de SQD.
Quelles applications sont les mieux adaptées aux services de requête SQD ?
Les tableaux de bord DeFi, les explorateurs de blockchain, les plateformes d'analyse on-chain, les systèmes de surveillance en temps réel, les applications multi-chaînes et les Agents IA — tout scénario nécessitant un accès fréquent aux données on-chain — sont idéaux pour les services de requête SQD.







