Futures
Accédez à des centaines de contrats perpétuels
CFD
Or
Une plateforme pour les actifs mondiaux
Options
Hot
Tradez des options classiques de style européen
Compte unifié
Maximiser l'efficacité de votre capital
Trading démo
Introduction au trading futures
Préparez-vous à trader des contrats futurs
Événements futures
Participez aux événements et gagnez
Demo Trading
Utiliser des fonds virtuels pour faire l'expérience du trading sans risque
Lancer
CandyDrop
Collecte des candies pour obtenir des airdrops
Launchpool
Staking rapide, Gagnez de potentiels nouveaux jetons
HODLer Airdrop
Conservez des GT et recevez d'énormes airdrops gratuitement
Pre-IPOs
Accédez à l'intégralité des introductions en bourse mondiales
Points Alpha
Tradez on-chain et gagnez des airdrops
Points Futures
Gagnez des points Futures et réclamez vos récompenses d’airdrop.
Investissement
Simple Earn
Gagner des intérêts avec des jetons inutilisés
Investissement automatique
Auto-invest régulier
Double investissement
Profitez de la volatilité du marché
Staking souple
Gagnez des récompenses grâce au staking flexible
Prêt Crypto
0 Fees
Mettre en gage un crypto pour en emprunter une autre
Centre de prêts
Centre de prêts intégré
Promotions
Centre d'activités
Participez et gagnez des récompenses
Parrainage
20 USDT
Invitez des amis et gagnez des récompenses
Programme d'affiliation
Obtenez des commissions exclusives
Gate Booster
Développez votre influence et gagnez des airdrops
Annoncement
Mises à jour en temps réel
Blog Gate
Articles sur le secteur de la crypto
AI
Gate AI
Votre assistant IA polyvalent pour toutes vos conversations
Gate AI Bot
Utilisez Gate AI directement dans votre application sociale
GateClaw
Gate Blue Lobster, prêt à l’emploi
Gate for AI Agent
Infrastructure IA, Gate MCP, Skills et CLI
Gate Skills Hub
+10K compétences
De la bureautique au trading, une bibliothèque de compétences tout-en-un pour exploiter pleinement l’IA
GateRouter
Choisissez intelligemment parmi plus de 40 modèles d’IA, avec 0 % de frais supplémentaires
L'IA ne peut toujours pas battre l'ingénieur d'astreinte : voici pourquoi
En résumé
Les entreprises d’IA continuent de proposer des agents autonomes d’ingénierie de la fiabilité du site — IA qui enquête sur les incidents de production à la place des humains. Datadog a effectué le benchmark réel sur de véritables pannes, et les meilleurs modèles d’IA ne peuvent pas encore surpasser les ingénieurs qu’ils sont censés remplacer. Le benchmark s’appelle ARFBench (Anomaly Reasoning Framework Benchmark), un projet conjoint de Datadog et Carnegie Mellon. Construit à partir de 63 incidents de production réels, extraits des fils Slack des ingénieurs lors d’urgences en direct — 750 questions à choix multiples couvrant 142 métriques de surveillance et 5,38 millions de points de données, chaque question vérifiée manuellement. Pas de données synthétiques. Pas de scénarios de manuel. “Des billions de dollars sont perdus chaque année en raison de pannes système”, écrivent les chercheurs. Le benchmark teste si l’IA peut réellement contribuer à changer cela.
« Malgré le rôle central de cette analyse basée sur des questions dans la réponse aux incidents, il reste incertain si les modèles fondamentaux modernes peuvent répondre de manière fiable aux types de questions sur les séries temporelles que les ingénieurs posent en pratique », indique le document. Les questions se divisent en trois niveaux. Niveau I : Existe-t-il une anomalie dans ce graphique ? Niveau II : Quand a-t-elle commencé, quelle en est la gravité, quel type ? Le Niveau III — le plus difficile — nécessite un raisonnement croisé entre métriques : Ce graphique cause-t-il le problème dans cet autre graphique ? C’est là que l’IA échoue. GPT-5 ne score que 47,5 % de F1 sur les questions de Niveau III, une métrique qui pénalise les modèles pour avoir deviné en choisissant la classe la plus courante.
« Malgré le rôle central de cette analyse basée sur des questions dans la réponse aux incidents, il reste incertain si les modèles fondamentaux modernes peuvent répondre de manière fiable aux types de questions sur les séries temporelles que les ingénieurs posent en pratique », écrivent les chercheurs. Comment chaque modèle s’est comporté GPT-5 a devancé tous les modèles existants avec 62,7 % de précision — lors d’un test où la devinette aléatoire obtient 24,5 %. Gemini 3 Pro a obtenu 58,1 %. Claude Opus 4.6 : 54,8 %. Claude Sonnet 4.5 : 47,2 %. Les experts du domaine ont atteint 72,7 % de précision. Les non-experts — chercheurs en séries temporelles chez Datadog sans expérience approfondie en observabilité — ont quand même réussi à 69,7 %. Aucun modèle d’IA n’a surpassé l’un ou l’autre des seuils humains.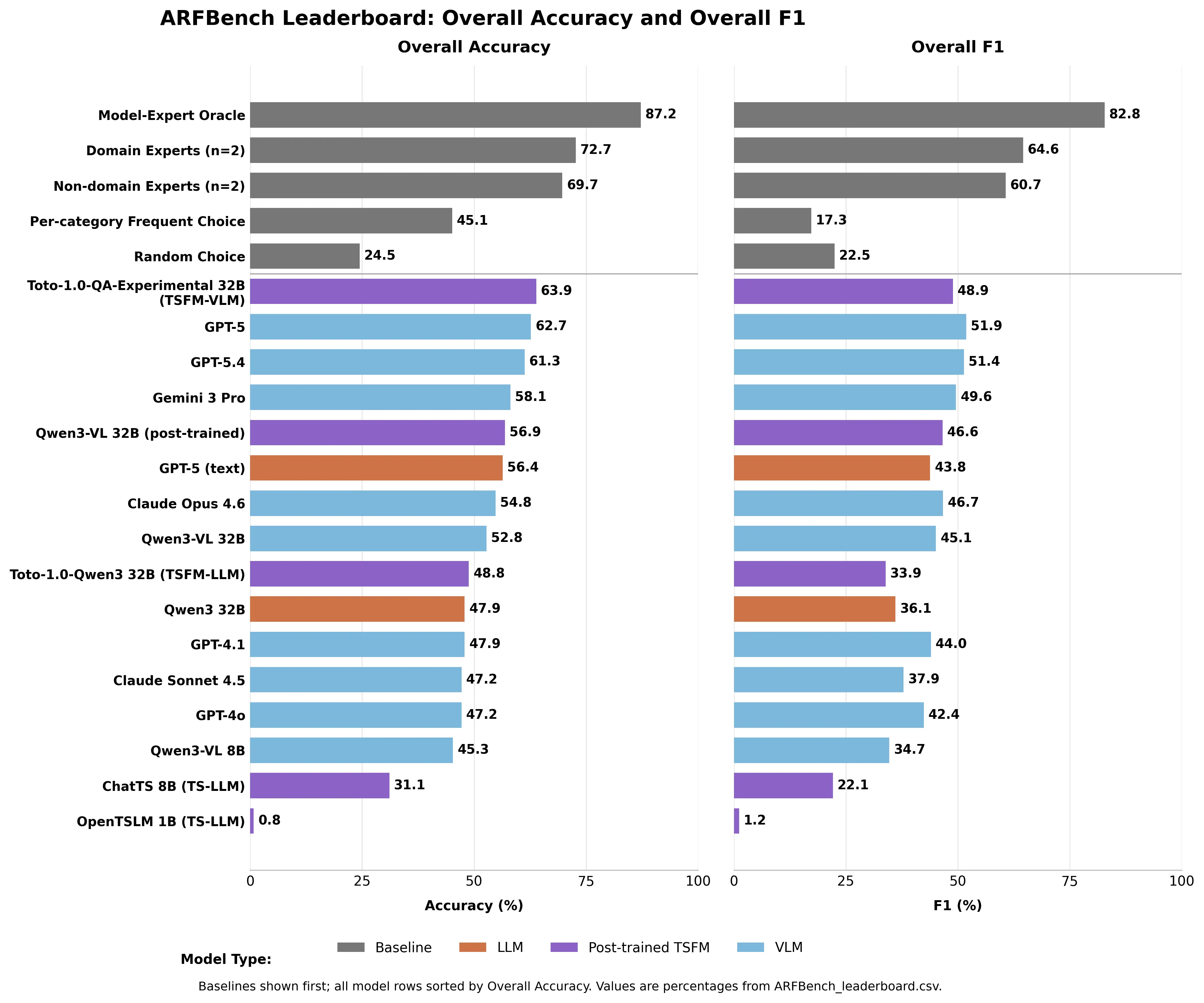
Image créée par Decrypt basée sur le CSV du classement ARFBench
Le modèle qui a réellement dominé le classement complet était l’hybride de Datadog : Toto — leur modèle interne de prévision de séries temporelles — combiné avec Qwen3-VL 32B. Toto-1.0-QA-Experimental a obtenu 63,9 % de précision, dépassant GPT-5 tout en utilisant une fraction de ses paramètres. Sur l’identification d’anomalies spécifiquement, il a surpassé tous les autres modèles d’au moins 8,8 points de pourcentage en F1. Un modèle de domaine spécialement conçu, entraîné sur des données d’observabilité, surpassant un système généraliste de pointe pour cette tâche spécifique, est le résultat attendu. C’est le but. La découverte la plus précieuse n’est pas celle du modèle ayant obtenu le meilleur score. « Nous observons des profils d’erreur sensiblement différents entre les modèles leaders et les experts humains, ce qui suggère que leurs forces sont complémentaires », écrivent les chercheurs. Les modèles hallucinent, manquent de métadonnées, perdent le contexte du domaine. Les humains mal interprètent des horodatages précis et échouent parfois sur des instructions complexes. Leurs erreurs se recoupent à peine.
Modélisez un « Modèle-Oracle Expert » théorique — un juge parfait qui choisit toujours la bonne réponse entre l’IA et l’humain — et vous obtenez 87,2 % de précision et 82,8 % de F1. Bien au-dessus de chacun seul. Ce n’est pas un produit. C’est un objectif documenté — construit à partir de véritables urgences, pas de jeux de données sélectionnés — qui quantifie précisément à quel point la collaboration humain-IA pourrait être meilleure. Le classement est en direct sur Hugging Face. GPT-5 est à 62,7 %. Le plafond est à 87,2 %.