Setelah kemajuan pesat kapabilitas model besar, perusahaan kini tidak lagi berfokus pada “apakah model tersedia,” tetapi pada “apakah model dapat beroperasi secara andal dan berkelanjutan di lingkungan bisnis nyata.” Klaster pelatihan memang dapat menggabungkan hash power, namun sistem produksi harus mampu menangani permintaan berkelanjutan, tail latency, iterasi versi, izin data, dan akuntabilitas insiden. Singkatnya, medan utama AI perusahaan bergeser ke inferensi dan kerangka operasional. Agen memperluas tantangan dari “Q&A satu putaran” menjadi “tugas multi-langkah, pemanggilan alat, dan manajemen status,” sehingga meningkatkan standar infrastruktur dan tata kelola.
Jika Anda memandang infrastruktur AI sebagai rantai yang berkelanjutan mulai dari chip, pusat data, hingga layanan dan tata kelola, artikel ini menyoroti titik akhirnya: layanan inferensi, akses data, dan tata kelola organisasi. Topik hulu seperti HBM, daya, dan pusat data lebih tepat dibahas dalam diskusi sisi pasokan; artikel ini mengasumsikan pembaca telah memahami arsitektur berlapis.
Mengapa “Production Inference” dan “Training Hash Power” Merupakan Tantangan yang Berbeda
Meski pelatihan dan inferensi menggunakan komponen perangkat keras serupa seperti GPU, jaringan, dan penyimpanan, tujuan optimasinya berbeda. Pelatihan menekankan throughput dan paralelisme jangka panjang; inferensi memprioritaskan concurrency, tail latency, biaya per permintaan, serta ritme rilis dan rollback versi. Bagi perusahaan, perbedaan berikut berdampak langsung pada pilihan arsitektur dan batas pengadaan:
-
Struktur biaya: Pelatihan umumnya berupa pengeluaran modal bertahap, sedangkan biaya inferensi meningkat linear seiring volume bisnis dan lebih sensitif terhadap caching, batching, routing, dan pemilihan model.
-
Definisi ketersediaan: Tugas pelatihan dapat diantrekan dan diulang; inferensi online biasanya terikat SLA, membutuhkan rate limiting, degradasi, dan strategi multi-replika.
-
Frekuensi perubahan: Pembaruan model, prompt, kebijakan alat, dan basis pengetahuan terjadi lebih sering, sehingga diperlukan proses rilis yang dapat diaudit, bukan deployment satu kali.
-
Batas data: Data pelatihan umumnya berada dalam lingkungan terkontrol, sedangkan inferensi sering mengakses data pelanggan, dokumen internal, dan antarmuka sistem bisnis, sehingga membutuhkan izin ketat dan masking data.
Karena itu, dalam menilai infrastruktur AI perusahaan, lebih efektif berfokus pada kapabilitas lapisan layanan—seperti gateway, routing, observability, rilis, izin, dan audit—daripada sekadar membandingkan skala klaster pelatihan.
Production-Grade Inference Stack: Dari Entry hingga Observability
Stack inferensi yang kokoh biasanya mencakup setidaknya modul-modul berikut. Meski vendor menggunakan nama produk berbeda, fungsi inti tetap sama.
API Gateway dan Tata Kelola Trafik
Titik masuk terpadu untuk autentikasi, kuota, rate limiting, dan terminasi TLS; saat membuka kapabilitas model secara eksternal, gateway adalah garis pertahanan pertama untuk keamanan dan strategi bisnis.
Routing Model dan Manajemen Versi
Perusahaan sering menjalankan banyak model sekaligus (untuk berbagai tugas, biaya, dan tingkat kepatuhan). Routing harus mendukung pemisahan berdasarkan tenant, skenario, dan tingkat risiko, serta rilis abu-abu dan rollback, agar tidak terjadi kegagalan akibat “penggantian sekaligus.”
Serialisasi, Batching, dan Caching
Pada concurrency tinggi, serialisasi/deserialisasi, strategi batching, serta desain cache KV atau semantik sangat memengaruhi tail latency dan biaya. Caching juga menimbulkan risiko konsistensi, sehingga diperlukan kebijakan invalidasi dan data sensitif yang jelas.
Vector Retrieval dan Integrasi RAG (Jika Berlaku)
Retrieval-augmented generation menghubungkan inferensi dengan sistem data: pembaruan indeks, filter izin, tampilan fragmen referensi, dan pengendalian risiko halusinasi merupakan bagian integral dari kerangka operasional, bukan sekadar “tambahan” di luar model.
Observability, Logging, dan Cost Accounting
Minimal, penggunaan token, persentil latency, dan jenis error harus dipecah berdasarkan tenant, versi model, dan kebijakan routing. Tanpa ini, perencanaan kapasitas sulit dilakukan dan review insiden tidak dapat mengidentifikasi secara akurat apakah masalah berasal dari model, data, atau gateway.
Modul-modul ini menentukan apakah pengalaman online stabil, biaya dapat dikendalikan, dan masalah dapat ditelusuri. Jika ada komponen yang hilang, sistem sering hanya tampil baik di demo beban rendah, tetapi menunjukkan cacat saat beban puncak atau perubahan terjadi.
Multi-Model dan Hybrid Deployment: Routing, Biaya, dan Kedaulatan Data
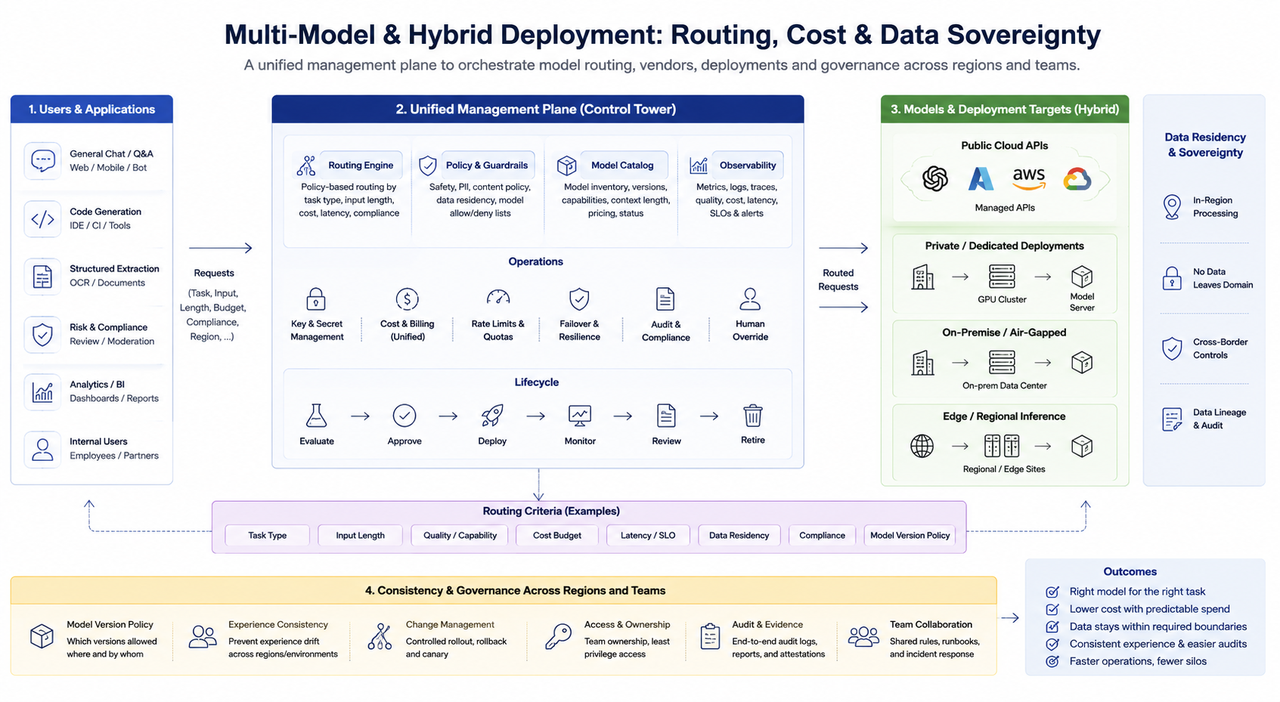
Di lingkungan perusahaan, umum bagi beberapa model untuk hidup berdampingan: tugas seperti percakapan umum, kode, ekstraksi terstruktur, dan review pengendalian risiko tidak cocok dengan satu model atau strategi parameter. Tantangan utama rekayasa setup multi-model meliputi:
-
Strategi routing: Memilih model berdasarkan jenis tugas, panjang input, batas biaya, dan persyaratan kepatuhan; membutuhkan strategi default yang dapat diinterpretasi dan override manual operasional.
-
Campuran vendor: API cloud publik, deployment on-premises, dan klaster khusus dapat hidup berdampingan; manajemen kunci terpadu, standar penagihan, dan failover penting untuk menghindari “vendor terisolasi.”
-
Hybrid cloud dan residensi data: Operasi finansial, pemerintahan, dan lintas negara sering membutuhkan data tetap di domain atau yurisdiksi tertentu; deployment inferensi membentuk arsitektur jaringan dan penempatan cache, berinteraksi dengan infrastruktur lapisan ketiga seperti pusat data, daya, dan jaringan regional.
-
Tata kelola konsistensi: Kebijakan yang jelas diperlukan untuk menentukan apakah bisnis yang sama di wilayah atau lingkungan berbeda dapat menggunakan versi model yang berbeda; jika tidak, akan terjadi drift pengalaman dan tantangan audit.
Dari perspektif organisasi, tantangan sistem multi-model bukan pada “jumlah model,” tetapi pada tidak adanya plane manajemen terpadu. Jika aturan routing, kunci, monitoring, dan proses rilis tersebar di berbagai tim, biaya troubleshooting dan kepatuhan meningkat pesat.
Agent: Orkestrasi, Batas Alat, dan Auditabilitas
Agen memperluas inferensi ke tugas multi-langkah: perencanaan, pemanggilan alat, operasi memori, dan generasi aksi berikutnya. Untuk sistem perusahaan, ini berarti permukaan risiko meluas dari “output teks” ke dampak eksekusi pada sistem eksternal.
Area utama yang perlu diperhatikan dalam praktik meliputi:
-
Whitelist alat dan least privilege: Setiap alat harus memiliki cakupan izin yang jelas (database read-only, API terbatas, jalur file terbatas, dll.) untuk menghindari “pemanggilan alat omnipotent” yang terlalu luas.
-
Kolaborasi manusia-mesin dan titik konfirmasi: Untuk aksi berisiko tinggi seperti transfer dana, perubahan izin, atau ekspor data massal, wajibkan alur konfirmasi atau persetujuan daripada otomatisasi penuh.
-
Status sesi dan batas memori: Memori jangka panjang melibatkan privasi dan siklus retensi; konteks jangka pendek memengaruhi biaya dan strategi pemotongan. Kebijakan tiering dan pembersihan data harus selaras dengan persyaratan kepatuhan.
-
Jejak audit: Catat “kapan model, berdasarkan konteks apa, memanggil alat apa, dan apa yang dikembalikan”; review insiden dan investigasi regulasi sering mengandalkan ini, bukan hanya jawaban akhir.
-
Sandbox dan isolasi: Eksekusi kode dan pemuatan plugin memerlukan lingkungan runtime terisolasi untuk mencegah prompt injection berkembang menjadi serangan tingkat eksekusi.
Agen memberikan nilai melalui otomatisasi, tetapi hanya jika batas-batasnya jelas. Jika batas tidak jelas, kompleksitas sistem dapat meningkat secara eksponensial, dan biaya operasional serta hukum dapat melonjak sebelum manfaat bisnis tercapai.
Keamanan dan Kepatuhan: “Minimum Set” untuk Peluncuran dan Operasi
Persyaratan kepatuhan bervariasi menurut industri, namun sistem produksi perusahaan setidaknya harus memenuhi “minimum set” berikut dan berkembang sesuai kebutuhan untuk memenuhi tuntutan regulasi.
-
Identitas dan akses: Akun layanan, akun pengguna, rotasi API key, dan prinsip least privilege; bedakan antara kredensial “pengembangan/pengujian” dan “produksi.”
-
Data dan privasi: Masking field sensitif, masking log, pemisahan data pelatihan dan inferensi; definisikan dan simpan perjanjian pemrosesan data dengan vendor model pihak ketiga secara jelas.
-
Supply chain model: Traceability sumber model, hash versi, dependensi, dan image container; cegah “unknown weights” masuk ke jalur produksi.
-
Keamanan konten dan pencegahan penyalahgunaan
-
Terapkan filter kebijakan pada input/output sesuai kebutuhan; lakukan rate limiting dan deteksi anomali untuk panggilan batch otomatis.
-
Respons insiden: Rollback model, switch routing, pencabutan kunci, prosedur notifikasi pelanggan; tentukan pihak bertanggung jawab dan jalur eskalasi secara jelas.
Kapabilitas ini tidak menggantikan pertahanan berlapis tim keamanan, tetapi penting untuk mengintegrasikan layanan AI ke dalam kerangka pengelolaan risiko perusahaan yang ada, bukan dibiarkan sebagai “pengecualian inovasi” jangka panjang.
Kesimpulan
Keunggulan kompetitif AI perusahaan kini bergeser dari “apakah model terbaru dapat diintegrasikan” menjadi “apakah banyak model dan agen dapat dioperasikan dengan biaya terkendali dan batas keamanan yang jelas.” Hal ini menuntut penguatan stack rekayasa dan tata kelola: routing dan rilis, observability dan manajemen biaya, izin alat dan jejak audit harus dianggap sebagai esensi produksi setara dengan model itu sendiri.








