AIリクエストルーティングは、マルチモデル推論リソースの管理を目的としたインフラ機能です。GPT、Claude、Gemini、DeepSeekといった大規模言語モデルが進化を続ける中、多くのAIアプリケーションが複数のモデルを同時に統合するようになっています。このような環境で、どのモデルをインテリジェントに選択するかが、AIシステム設計における重要な課題となっています。
Gate.AIは、アプリケーションとモデルサービスの中間に位置し、AIゲートウェイおよびモデルルーティングレイヤーとして機能します。マルチモデルアーキテクチャが業界標準となるにつれ、モデルルーティングはシステムパフォーマンスだけでなく、コスト管理、サービス安定性、AIエージェントの自律機能にも影響を及ぼします。
AIリクエストルーティングとは
AIリクエストルーティングは、タスクの特性に応じて自動的に対象モデルを選択するスケジューリングメカニズムです。従来のアーキテクチャでは、アプリケーションが単一の固定モデルを呼び出して推論タスクを完了するのが一般的でした。マルチモデルアーキテクチャでは、各モデルが推論能力、コード生成、長文処理、コスト効率など、異なる強みを発揮します。
モデルルーティングレイヤーがリクエスト内容を分析し、最適なモデルに振り分けることで、リソース全体の利用率が向上します。
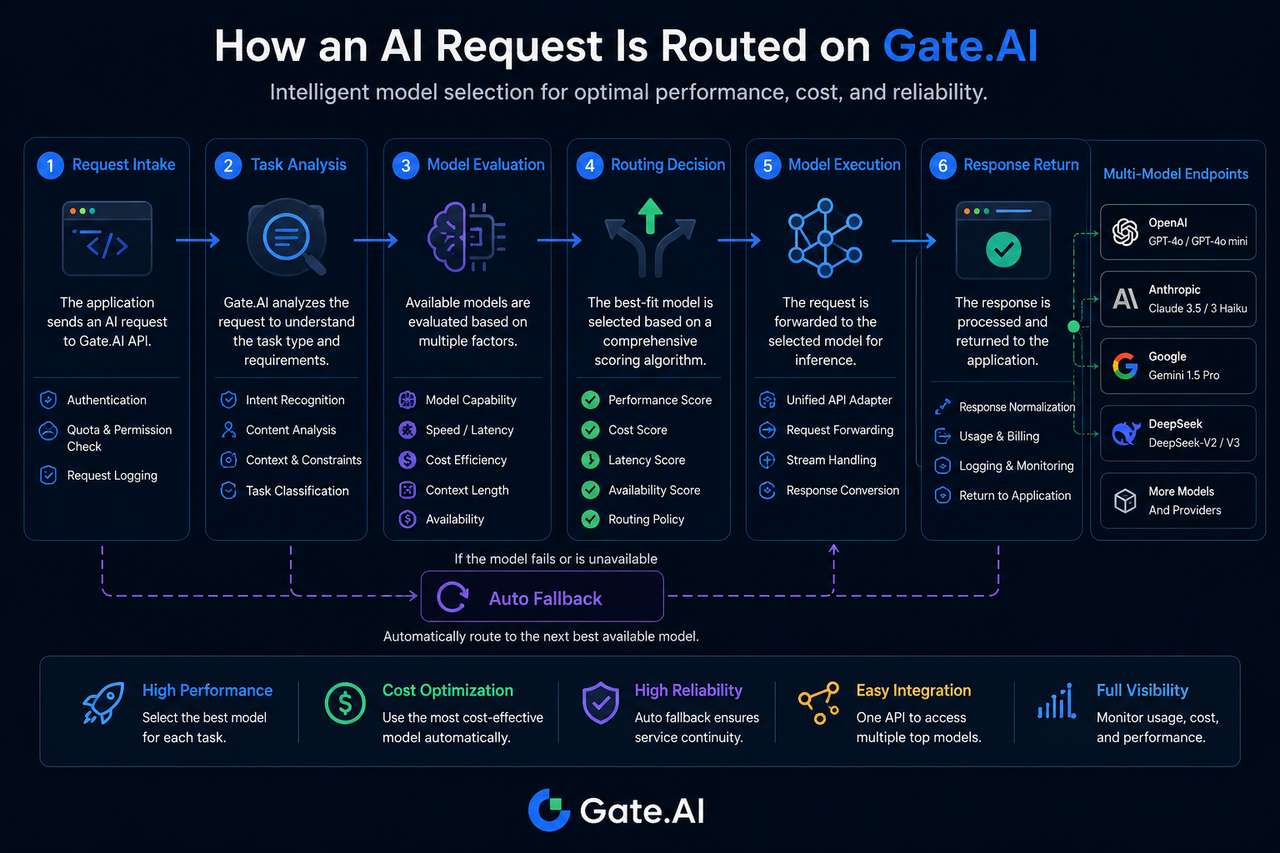
ステップ1:AIリクエストがGate.AIに到着
ルーティングプロセスは、リクエストの受け付けから始まります。
アプリケーションがリクエストを送信すると、最初にGate.AIゲートウェイレイヤーに到達します。この段階で、システムは認証情報の確認、アクセス権限のチェック、リクエストパラメータの記録を行います。
リクエスト内容には通常、以下の項目が含まれます。
- ユーザー入力
- モデル設定
- トークン制限
- 応答フォーマット要件
- 呼び出し戦略
検証が完了すると、リクエストは次の分析フェーズに進みます。
ステップ2:システムがタスクタイプを分析
タスクの識別は、モデルルーティングの中核を担います。
Gate.AIはリクエストの特性からタスクタイプを判断します。例えば以下のようなタスクが該当します。
- 一般会話
- 長文要約
- コンテンツ作成
- コード生成
- データ分析
- エージェントツール呼び出し
タスクによってモデルに求められる能力は大きく異なります。タスクを正確に識別することで、その後のモデルマッチングが効率的に進みます。
ステップ3:モデル能力の評価とマッチング
モデル評価フェーズでは、候補となるモデルの範囲を決定します。
システムはモデル能力データベースを参照し、現在利用可能なモデルを絞り込みます。
評価の軸として、以下の項目が一般的です。
- 推論能力
- コンテキスト長
- 応答速度
- ツール呼び出し能力
- マルチモーダル対応
- コストレベル
例えば、複雑な推論タスクでは推論能力の高いモデルが優先され、長文書処理タスクでは超長コンテキストウィンドウに対応したモデルが選ばれやすくなります。
ステップ4:ルーティング決定の生成
ルーティング決定フェーズでは、最終的に実行するモデルを確定します。
候補モデルが特定された後、システムは複数の指標を組み合わせてスコアリングを行います。
主な判断材料は以下のとおりです。
モデルパフォーマンス
モデルのパフォーマンスは、タスク完了の質を左右します。
複雑な問題には強力な論理的推論が求められますが、単純なタスクでは必ずしも最高性能のモデルは必要ありません。
応答レイテンシ
応答速度はユーザー体験に直結します。
リアルタイム対話のシナリオでは、低レイテンシモデルが優先される傾向があります。
呼び出しコスト
推論コストはモデルごとに異なります。
同じタスクを複数のモデルで実行できる場合、リソース効率の高いモデルが優先されることがあります。
サービス可用性
モデルの状態もルーティング決定において重要な要素です。
モデルがレート制限中、障害発生中、または混雑している場合、システムは自動的にその優先度を引き下げます。
ステップ5:リクエストを対象モデルに送信
ルーティング決定後、リクエストは対象モデルに転送されます。
この段階でGate.AIは、モデルプロバイダー間のインターフェースの違いを統一的に処理します。
アプリケーション開発者は、モデルごとに個別のインターフェースを開発する必要がありません。統一されたアクセスレイヤーにより、開発の複雑さが軽減され、システムの拡張性が向上します。
ステップ6:モデルが結果を生成して返送
対象モデルが推論を完了すると、結果がGate.AIに返されます。
Gate.AIは応答を標準化し、異なるモデルからのデータ構造を統一します。
出力フォーマットが統一されることで、アプリケーション層での適応作業が減り、システム統合が容易になります。
最終結果はアプリケーションまたはAIエージェントに返されます。
対象モデルが利用不可の場合はどうなりますか?
モデルが利用不可になることは、マルチモデルエコシステムではよく発生します。
対象モデルがタイムアウト、レート制限、サービス異常に陥った場合、Gate.AIは自動フォールバック処理を開始します。システムは事前に設定されたポリシーに従ってバックアップモデルを再選択し、タスクを継続します。
この仕組みにより、単一障害点のリスクが軽減され、サービス全体の継続性が向上します。
このプロセスの詳細については、「AIモデルに障害が発生した場合の処理方法:Gate.AIの自動フォールバックメカニズムの完全フロー分析」をご参照ください。
AIリクエストルーティング処理の例
以下は、コンテンツ生成タスクにおける典型的なフローの例です。
| フェーズ | システムの動作 |
|---|---|
| リクエストアクセス | アプリケーションが生成リクエストを送信 |
| タスク分析 | 長文コンテンツ作成として識別 |
| モデルフィルタリング | 長コンテキスト対応の候補モデルを選定 |
| ルーティング決定 | パフォーマンス、コスト、レイテンシでスコアリング |
| モデル実行 | リクエストを対象モデルに送信 |
| 結果処理 | 標準化された出力を返送 |
| 障害復旧 | 必要に応じてバックアップモデルに自動切替 |
このプロセスは通常ごく短時間で完了し、ユーザーが背後で行われているモデル選択に気づくことはほとんどありません。
まとめ
AIリクエストルーティングは、AIゲートウェイの中核機能であり、複数の大規模言語モデルの中からタスクに最適なモデルを動的に選択します。固定の単一モデル呼び出しと比較して、モデルルーティングは各モデルの強みを最大限に活かし、システムの柔軟性、安定性、リソース利用率を高めます。
Gate.AIのアーキテクチャでは、AIリクエストはリクエストアクセス、タスク識別、モデル評価、ルーティング決定、モデル実行、結果返送という複数の段階を経ます。
よくある質問
Gate.AIにモデルルーティングが必要な理由は?
Gate.AIは複数のAIモデルエコシステムと連携しており、各モデルは推論、コード生成、長文処理など、異なる分野で優位性を持っています。モデルルーティングは、タスクの要件に応じて最適なモデルを自動的に選択します。
1つのAIリクエストで複数のモデルを同時に呼び出せますか?
通常、1つのAIリクエストは1つの対象モデルで実行されます。ただし、複雑なシナリオでは、マルチモデル連携パターンを用い、異なるモデルがタスクの各部分を分担する場合もあります。
AIルーティング決定では主にどのような要素が考慮されますか?
AIルーティング決定では、モデルパフォーマンス、応答速度、推論コスト、コンテキスト長、ツール呼び出し能力、サービス可用性など、複数の要素が総合的に評価されます。
モデルルーティングとロードバランシングの違いは?
ロードバランシングが主にトラフィック分散を目的とするのに対し、モデルルーティングはモデルの能力マッチングに焦点を当てています。モデルルーティングは、タスクの特性に基づいて最適なモデルを選択するものであり、単にリクエストトラフィックを分散するものではありません。
共有
内容


関連記事

ONDOトークン経済モデル:プラットフォームの成長とユーザーエンゲージメントをどのように推進するのか

Render、io.net、Akash:DePINハッシュレートネットワークの比較分析

AI分野におけるRenderの申請理由:分散型ハッシュレートが人工知能の発展を支える仕組み

SentioとThe Graph:リアルタイムインデックス機構とサブグラフインデックス機構の比較

USD.AI 収益源分析:AIインフラ借入資金による収益創出の仕組み
