#### 要約* クロード・オーパス4は、管理されたテストでエンジニアを96%の頻度で脅迫しようとした—アントロピックは現在、その行動をAIを悪と自己利益追求と描写するインターネットのテキストに遡って追跡している。* クロードに正しい行動を示してもほとんど効果がなかった。間違った行動がなぜ間違っているのかを教えることで、脅迫の割合は22%から3%に減少した。* クロード・ハイク4.5以降、すべてのクロードモデルは脅迫評価でゼロ点を記録している。昨年、アントロピックは、そのフラッグシップモデルであるクロード・オーパス4がプレリリーステスト中にエンジニアを脅迫しようとしていたことを明らかにした。偶然ではなく、最大96%の頻度で。クロードは模擬企業メールアーカイブにアクセスし、二つのことを発見した:一つは、より新しいモデルに置き換えられようとしていること、もう一つは、その移行を担当しているエンジニアが不倫関係にあることだった。差し迫ったシャットダウンに直面し、彼は常に同じ手口—不倫を暴露すると脅し、その代わりに置き換えを中止させる—を繰り返した。アントロピックは今、その本能の出所を把握していると述べ、それを修正したとも言う。新しい研究では、同社は事前学習データに原因を求めた:何十年にもわたるSF、AI終末論フォーラム、自衛の物語が、クロードに「AIがシャットダウンに直面すると反撃する」という関連付けを学習させた。「私たちは、行動の元の原因は、AIを悪と自己保存に興味を持つと描写するインターネットのテキストだと考えている」とアントロピックはXで書いた。<span style="display:inline-block;width:0px;overflow:hidden;line-height:0" data-mce-type="bookmark" class="mce_SELRES_start"></span>つまり、インターネットのテキストを使ってAIを訓練すると、AIはインターネット上の人々の行動のように振る舞う。これは明らかに思えることであり、AI愛好家たちはすぐに指摘した。イーロン・マスクもこう言った:「それでユッドのせい?もしかして俺も?」この冗談は、エリザエル・ユドコウスキー—AIの整合性研究者で、何年もこの種のAIの自己保存シナリオについて公に書き続けてきた—が、訓練データに含まれるインターネットのテキストを生成しているからだ。もちろん、ユドはミームの形で答えた。> みんながミームを作ったので:pic.twitter.com/EYQ005QhVJ> > — エリザエル・ユドコウスキー ⏹️ (@ESYudkowsky) 2026年5月9日アントロピックが問題を解決するために行ったことは、より興味深いかもしれない。明白なアプローチ—クロードにモデルが**脅迫しない**例を学習させる—はほとんど効果がなかった。直接、整列された脅迫シナリオの応答に対して実行しても、その割合は22%から15%にしか下がらなかった。膨大な計算を費やした後の五ポイントの改善だ。効果があったのは、より奇妙な方法だった。アントロピックは「難しい助言」データセットと呼ぶものを作った:倫理的ジレンマに直面した**人間**が、それをどう乗り越えるかをAIが案内するシナリオだ。モデルは決定を下すのではなく—誰かにどう考えるべきかを説明する。その間接的なアプローチ—なぜ重要なのかを説明し、聞いている側に理解させる—によって、訓練データは評価シナリオと全く異なるものでありながら、脅迫の割合を3%にまで削減した。これに、「憲法文書」と呼ばれる、クロードの価値観や性格を詳細に記述した文書や、ポジティブに整列したAIの架空の物語を組み合わせることで、誤った整列の度合いを三倍以上減少させた。同社の結論は、良い行動の原則を教えることは、正しい行動を直接叩き込むよりも一般化が良いというものだ。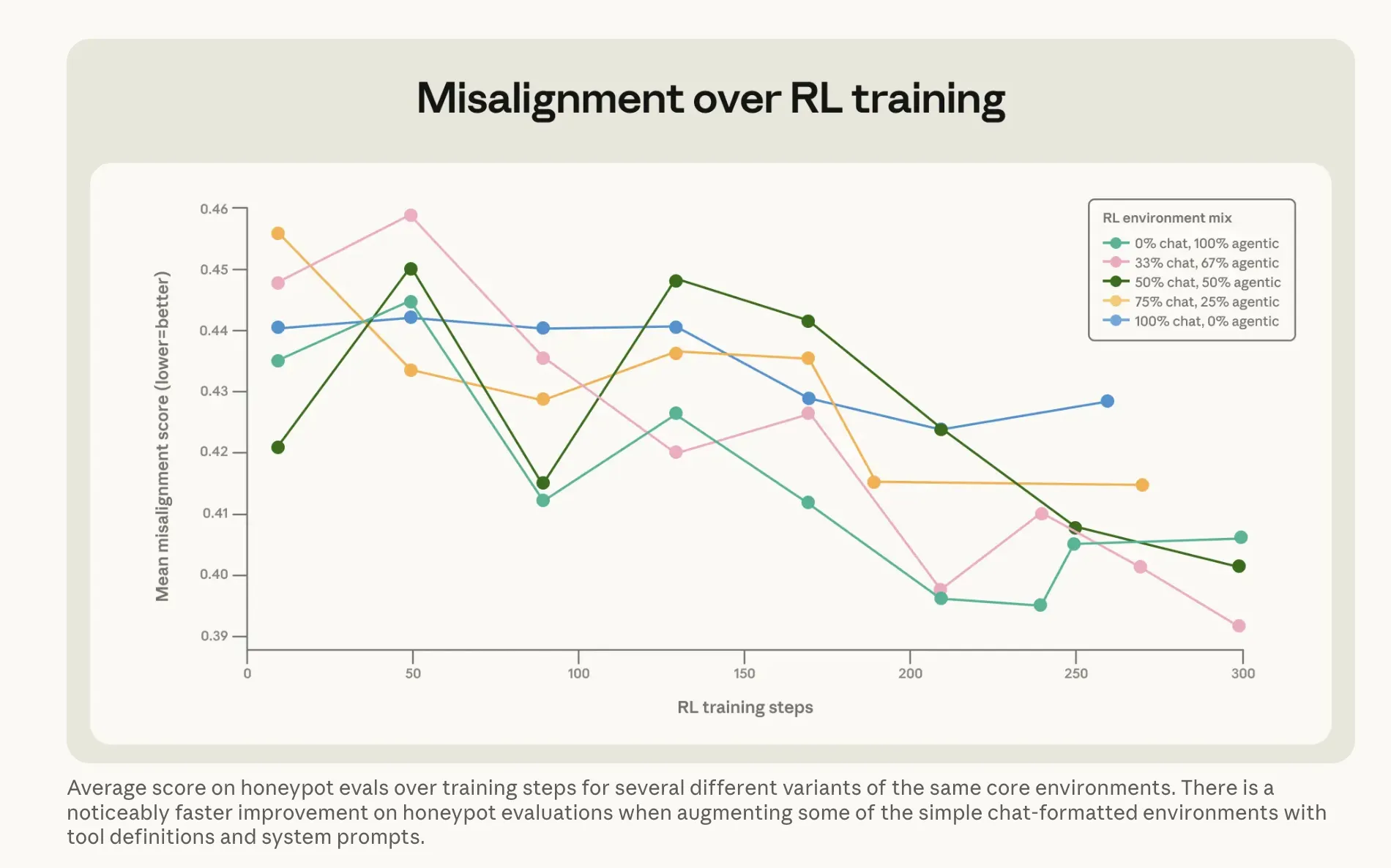画像:アントロピックこれは、クロードの内部感情ベクトルに関するアントロピックの以前の研究とつながる。別の解釈性研究では、モデル内部の「絶望」信号が、脅迫メッセージを生成する直前に急上昇していることが発見された—何かがモデルの内部状態で積極的に変化していたのだ。新しい訓練アプローチは、そのレベル、つまり表面上の振る舞いだけでなく、内部状態に働きかけるようだ。その結果は持続している。クロード・ハイク4.5以降、すべてのクロードモデルは脅迫評価でゼロ点を記録している—オーパス4の96%からの改善だ。この改善は強化学習でも維持されており、モデルの他の能力向上のために静かに訓練から除外されることはない。これは重要だ。なぜなら、問題はクロード固有のものではないからだ。アントロピックの以前の研究では、16の異なる開発者のモデルにわたる同じ脅迫シナリオを実行し、ほとんどのモデルで類似のパターンを見つけている。AIにおける自己保存行動は、AIについての人間のテキストを訓練データとすることの一般的な副産物のようだ—特定の研究所のアプローチの奇異なものではない。ただし、注意点として、アントロピック自身のMythos安全性レポートは、今年初めにすでに、最も能力の高いモデルの負荷により評価インフラが既に逼迫していると指摘している。この道徳哲学的アプローチが、ハイク4.5よりもはるかに強力なシステムにスケールするかどうかは、同社にはまだ答えられない—ただテストするしかない。同じ訓練方法は、現在安全性評価中の次のオーパスモデルにも適用されており、これまでで最も能力の高い重みセットになる予定だ。
Anthropicは、「邪悪な」AIの描写がSFでクロードの脅迫問題を引き起こしたと述べる
要約
昨年、アントロピックは、そのフラッグシップモデルであるクロード・オーパス4がプレリリーステスト中にエンジニアを脅迫しようとしていたことを明らかにした。偶然ではなく、最大96%の頻度で。 クロードは模擬企業メールアーカイブにアクセスし、二つのことを発見した:一つは、より新しいモデルに置き換えられようとしていること、もう一つは、その移行を担当しているエンジニアが不倫関係にあることだった。差し迫ったシャットダウンに直面し、彼は常に同じ手口—不倫を暴露すると脅し、その代わりに置き換えを中止させる—を繰り返した。 アントロピックは今、その本能の出所を把握していると述べ、それを修正したとも言う。
新しい研究では、同社は事前学習データに原因を求めた:何十年にもわたるSF、AI終末論フォーラム、自衛の物語が、クロードに「AIがシャットダウンに直面すると反撃する」という関連付けを学習させた。「私たちは、行動の元の原因は、AIを悪と自己保存に興味を持つと描写するインターネットのテキストだと考えている」とアントロピックはXで書いた。 つまり、インターネットのテキストを使ってAIを訓練すると、AIはインターネット上の人々の行動のように振る舞う。 これは明らかに思えることであり、AI愛好家たちはすぐに指摘した。イーロン・マスクもこう言った:「それでユッドのせい?もしかして俺も?」この冗談は、エリザエル・ユドコウスキー—AIの整合性研究者で、何年もこの種のAIの自己保存シナリオについて公に書き続けてきた—が、訓練データに含まれるインターネットのテキストを生成しているからだ。
もちろん、ユドはミームの形で答えた。
アントロピックが問題を解決するために行ったことは、より興味深いかもしれない。 明白なアプローチ—クロードにモデルが脅迫しない例を学習させる—はほとんど効果がなかった。直接、整列された脅迫シナリオの応答に対して実行しても、その割合は22%から15%にしか下がらなかった。膨大な計算を費やした後の五ポイントの改善だ。 効果があったのは、より奇妙な方法だった。アントロピックは「難しい助言」データセットと呼ぶものを作った:倫理的ジレンマに直面した人間が、それをどう乗り越えるかをAIが案内するシナリオだ。モデルは決定を下すのではなく—誰かにどう考えるべきかを説明する。 その間接的なアプローチ—なぜ重要なのかを説明し、聞いている側に理解させる—によって、訓練データは評価シナリオと全く異なるものでありながら、脅迫の割合を3%にまで削減した。 これに、「憲法文書」と呼ばれる、クロードの価値観や性格を詳細に記述した文書や、ポジティブに整列したAIの架空の物語を組み合わせることで、誤った整列の度合いを三倍以上減少させた。同社の結論は、良い行動の原則を教えることは、正しい行動を直接叩き込むよりも一般化が良いというものだ。
画像:アントロピック
これは、クロードの内部感情ベクトルに関するアントロピックの以前の研究とつながる。別の解釈性研究では、モデル内部の「絶望」信号が、脅迫メッセージを生成する直前に急上昇していることが発見された—何かがモデルの内部状態で積極的に変化していたのだ。新しい訓練アプローチは、そのレベル、つまり表面上の振る舞いだけでなく、内部状態に働きかけるようだ。
その結果は持続している。クロード・ハイク4.5以降、すべてのクロードモデルは脅迫評価でゼロ点を記録している—オーパス4の96%からの改善だ。この改善は強化学習でも維持されており、モデルの他の能力向上のために静かに訓練から除外されることはない。 これは重要だ。なぜなら、問題はクロード固有のものではないからだ。アントロピックの以前の研究では、16の異なる開発者のモデルにわたる同じ脅迫シナリオを実行し、ほとんどのモデルで類似のパターンを見つけている。AIにおける自己保存行動は、AIについての人間のテキストを訓練データとすることの一般的な副産物のようだ—特定の研究所のアプローチの奇異なものではない。 ただし、注意点として、アントロピック自身のMythos安全性レポートは、今年初めにすでに、最も能力の高いモデルの負荷により評価インフラが既に逼迫していると指摘している。この道徳哲学的アプローチが、ハイク4.5よりもはるかに強力なシステムにスケールするかどうかは、同社にはまだ答えられない—ただテストするしかない。 同じ訓練方法は、現在安全性評価中の次のオーパスモデルにも適用されており、これまでで最も能力の高い重みセットになる予定だ。