À mesure que les charges de travail d’inférence évoluent des clusters de test vers des applications commerciales concrètes, la solution optimale par défaut n’est plus systématiquement « tout centralisé dans des centres de données ultra-grands ». Cet article analyse la logique stratifiée des nœuds edge, des centres de données régionaux et des clusters centraux selon la latence, la bande passante, la disponibilité et la conformité. Il détaille les enjeux du partitionnement des tâches, des frontières de données et de la gouvernance opérationnelle dans des topologies hybrides, puis offre une comparaison avec la chaîne d’infrastructure IA globale.
Les discours publics assimilent souvent la puissance de hachage IA à « centres de données ultra-grands et GPU haut de gamme ». Pour l’entraînement et certains scénarios d’inférence centralisée, cette définition s’applique généralement. Infrastructure IA propose des requêtes d’inférence distribuées, sensibles à la latence, et exigeant que les données restent dans leur domaine, tandis que les interruptions réseau ou la congestion en période de pointe sont inacceptables. Dans ces cas, la topologie d’inférence devient un enjeu d’infrastructure : la puissance de hachage doit être disponible et localisée « au bon endroit et au bon niveau du réseau ».
Si l’infrastructure IA est perçue comme une chaîne continue, du niveau puce jusqu’aux services et à la gouvernance, cet article se concentre sur la topologie et les modes de déploiement : comment répartir la puissance de calcul et les données entre les couches edge, régionales et centrales afin d’équilibrer latence, coût, disponibilité et conformité. Les sujets amont comme l’alimentation, le packaging et la HBM concernent l’offre, tandis que le routage multi-modèles et la gouvernance des agents complètent les opérations de production.
Pourquoi aborder la « topologie d’inférence distribuée »
L’inférence centralisée offre des opérations unifiées, une flexibilité de mise à l’échelle et une utilisation optimale des ressources. Toutefois, dès que l’activité présente l’une des caractéristiques suivantes, les choix de topologie influent fortement sur l’expérience et le coût :
-
Contraintes de latence : contrôle industriel, interaction en temps réel, liens audio/vidéo et points de vente hors ligne sont sensibles à la latence extrême ; des chemins de retour trop longs amplifient la gigue.
-
Souveraineté et résidence des données : informations personnelles, transactions financières, services publics et santé exigent souvent que les données restent dans le domaine, sur le territoire ou dans une région désignée.
-
Bande passante de retour et coût : de nombreux points d’accès téléversent en continu des données brutes vers l’inférence centrale, rendant le backbone réseau et les frais de sortie des coûts majeurs potentiels.
-
Disponibilité et résilience : en cas de panne sur le réseau étendu, de fluctuations DNS ou de congestion inter-régions, les architectures purement centrales sont plus exposées au risque de « non-disponibilité généralisée ».
-
Réseau hors ligne ou faible : dans les mines, les navires ou certains sites industriels, il faut une capacité opérationnelle locale, sans dépendre d’une connectivité en ligne temps réel.
Ces défis ne peuvent être résolus par « des modèles centraux plus puissants », car leur origine se situe dans la distance physique, les chemins réseau et les frontières réglementaires — pas dans la puissance de hachage maximale d’une seule inférence.
Déploiement stratifié : utilité des couches edge, régionales et centrales
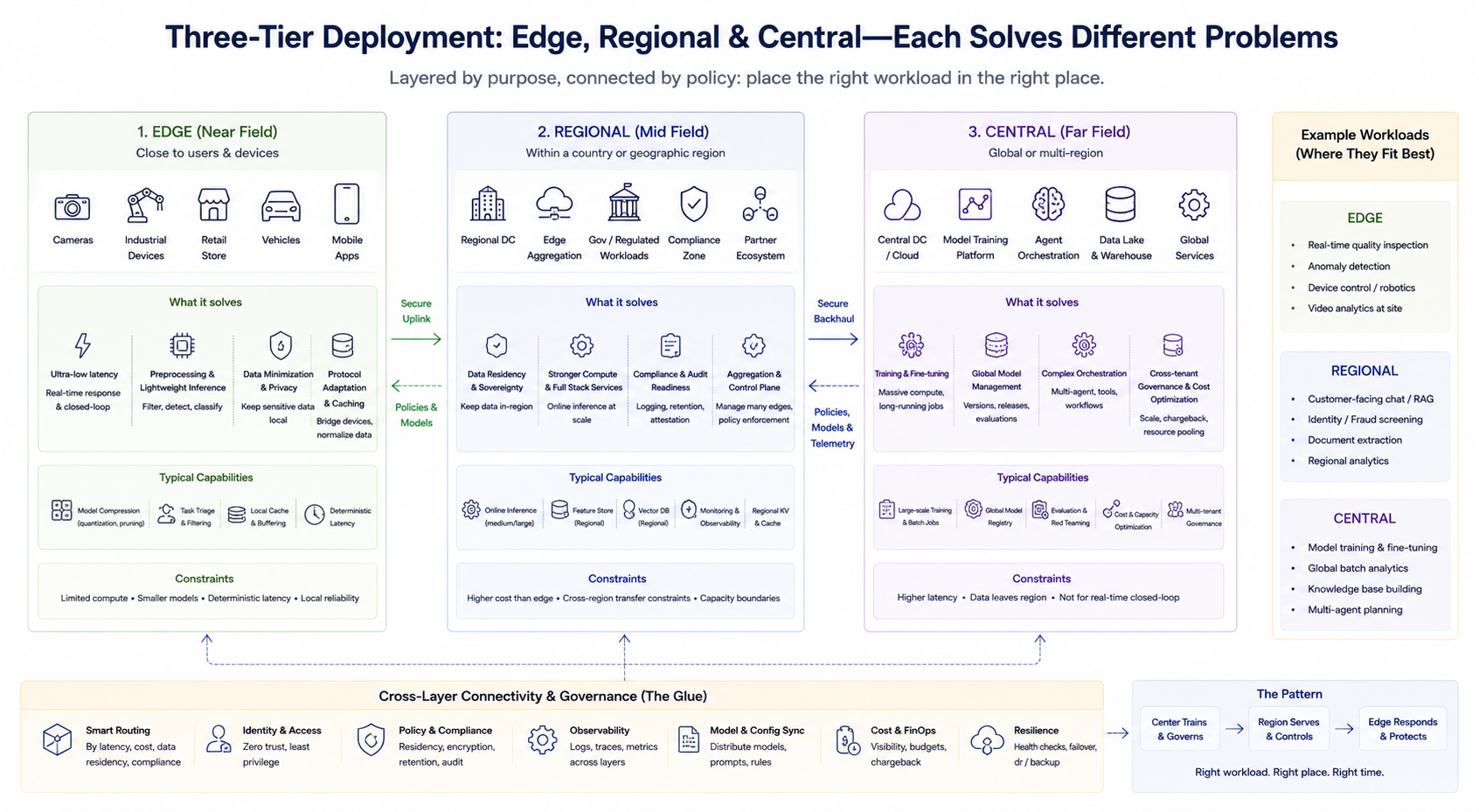
L’approche technique n’est pas un choix binaire, mais une combinaison stratifiée. Un cadre simplifié clarifie les rôles de chaque couche (la terminologie varie selon les fournisseurs) :
Couche edge (proximité)
Située près des utilisateurs ou des appareils, elle gère le prétraitement à faible latence, l’inférence légère, le cache et l’adaptation protocolaire. Elle convient aux boucles fermées temps réel et à la réduction des téléversements de données sensibles. La puissance de hachage edge étant limitée, la compression de modèle, la réduction de tâche et la latence déterministe sont privilégiées.
Couche régionale (champ intermédiaire)
Offre une puissance de hachage supérieure et une pile de services plus complète dans des pays ou régions spécifiques, répondant aux exigences de résidence des données, d’audit de conformité et d’inférence agrégée à moyenne échelle. Elle sert aussi de plan d’agrégation et de contrôle pour plusieurs nœuds edge.
Couche centrale (champ lointain)
Gère l’entraînement, le traitement par lots à grande échelle, la gestion globale des modèles, l’orchestration complexe des agents, la gouvernance inter-locataires unifiée et l’optimisation des coûts. Elle est adaptée aux charges de travail moins sensibles à la latence mais nécessitant une puissance de hachage élevée et l’agrégation des données.
Ces trois couches ne sont pas fixes, mais segmentées selon les tâches métier. Les entreprises peuvent opérer simultanément un entraînement central, une inférence en ligne régionale et une détection edge en temps réel, routant les requêtes vers la couche appropriée selon la stratégie.
Partitionnement des tâches : edge ou centre ?
Les principes de partitionnement reposent sur quatre axes : minimisation des données, budget de latence, complexité du modèle et fréquence de mise à jour.
Tâches adaptées à l’edge (puissance de hachage requise disponible) :
-
Extraction de caractéristiques temps réel, détection d’objets, contrôles qualité ponctuels, boucles fermées à faible latence
-
Inférence légère après désensibilisation locale (téléversement de vecteurs de caractéristiques plutôt que de médias bruts)
-
Stratégies d’inférence de secours et de hit cache en réseau faible
Tâches adaptées au centre ou à la région :
-
Workflows agents nécessitant un contexte large, des modèles puissants, des chaînes d’outils complexes ou une orchestration multi-systèmes
-
Inférence analytique nécessitant l’agrégation de données inter-départements
-
Appels sensibles nécessitant un audit centralisé et une gestion unifiée des clés
Les erreurs courantes incluent forcer de gros modèles avec un long contexte sur l’edge (OOM) ou envoyer des boucles fermées à faible latence au centre (perturbation du rythme de production). La conception de topologie vise à placer la charge de travail au bon endroit, selon les contraintes.
Les exigences de souveraineté des données modifient directement la forme du déploiement d’inférence. Les modèles peuvent être téléchargés localement, mais logs, caches, index de vecteurs et traces d’appels posent toujours des risques de conformité. Les questions clés :
-
Quelles données doivent être stockées et calculées à l’edge ou au niveau régional
-
Quels métadonnées peuvent quitter la région ou aller vers le cloud, et si anonymisation et périodes de rétention sont nécessaires
-
Si l’utilisation inter-région de différentes versions de modèles et fournisseurs est autorisée (éviter la « dérive de conformité »)
-
Si, lors de l’audit et des investigations, la sortie peut être reconstruite comme « générée à un endroit, à une heure précise, à partir de fragments de données spécifiques »
Les réponses à ces questions déterminent souvent la mise en production d’un système, plus que « si le modèle est open source ». Autrement dit, la conformité est une condition d’entrée pour la conception de topologie, pas un add-on pour l’inférence edge.
Réseau, énergie et opérations : coûts du déploiement distribué
L’inférence distribuée engendre des coûts systémiques à évaluer explicitement lors de la planification :
-
Réseau : l’augmentation des nœuds edge et régionaux complexifie la gestion des certificats, lignes dédiées / SD‑WAN, DNS et planification du trafic. La latence extrême est plus difficile à maîtriser en conditions multipath.
-
Énergie et centres de données : sites edge dispersés, efficacité énergétique et refroidissement par unité de puissance de hachage souvent inférieurs à ceux des grands centres ; les centres régionaux sont intermédiaires. Le rythme d’approvisionnement en énergie et racks limite toujours la vitesse d’expansion, mais la contrainte passe du « campus unique » au « multi-points parallèles ».
-
Opérations et cohérence des versions : modèles, prompts, stratégies de routage et index déployés sur plusieurs points peuvent dériver. Pipelines de déploiement unifiés, stratégies de rollback et checks de santé sont nécessaires, sinon les coûts de troubleshooting érodent rapidement les gains de latence apportés par l’edge.
-
Extension du périmètre de sécurité : plus de nœuds implique plus de certificats, plus de points d’entrée, plus de supports de stockage locaux. Sécurité physique et cycles de patch à l’edge souvent plus faibles qu’en centre de données central, nécessitant des stratégies ciblées de privilège minimum et de contrôle à distance.
La topologie distribuée ne consiste pas à « pousser la puissance de hachage plus loin », mais à déplacer une partie de la complexité opérationnelle et de gouvernance vers le site métier. Si les capacités organisationnelles et les outils plateforme ne suivent pas, les avantages de la topologie sont difficiles à concrétiser.
Relation avec l’inférence centralisée : mise en œuvre des architectures hybrides
Les solutions matures adoptent des architectures hybrides : le centre gère l’entraînement, les politiques globales et les charges lourdes ; la région gère les services en ligne dans les zones de conformité ; l’edge assure la faible latence et la résilience locale. Les schémas techniques courants incluent :
-
Cache stratifié et réutilisation des résultats : l’edge sert les requêtes à haute fréquence, les misses sont renvoyés au centre. Les clés de cache, TTL et politiques de données sensibles doivent être définis.
-
Split de modèle et front-end petit modèle : l’edge exécute des petits modèles de détection ou de classification, le centre gère la fusion de gros modèles et la génération d’interprétation (selon le scénario).
-
Retour asynchrone et agrégation : l’edge prend des décisions temps réel, puis renvoie de façon asynchrone des échantillons désensibilisés ou des métriques pour l’itération et la surveillance du modèle.
-
Plan de contrôle unifié : routage, quotas, monitoring et gestion des clés sont centralisés autant que possible, avec exécution décentralisée, pour réduire le risque de « chaque edge comme île isolée ».
La réussite des architectures hybrides repose sur un plan de contrôle unifié et un plan d’exécution stratifié — pas simplement sur l’augmentation du nombre de nœuds.
Conclusion
L’essence de l’inférence edge et distribuée n’est pas un « slogan de décentralisation », mais des arbitrages techniques entre latence, bande passante, conformité et coût opérationnel. À mesure que l’activité passe du démonstrateur à l’échelle, les choix de topologie façonnent modèles, architectures réseau et processus organisationnels. Négliger cette couche peut entraîner une puissance de hachage centrale forte mais une instabilité persistante en première ligne.








