Avec la DeFi, les plateformes d'analyse on-chain, les explorateurs de blockchain et les Agents IA qui stimulent une demande toujours croissante de données on-chain, les réseaux d'indexation de données sont devenus un pilier de l'infrastructure Web3. Comprendre les différences entre SQD et The Graph permet de mieux saisir la direction actuelle de la couche de données Web3 et les caractéristiques distinctives des différentes approches techniques.
Qu'est-ce que SQD
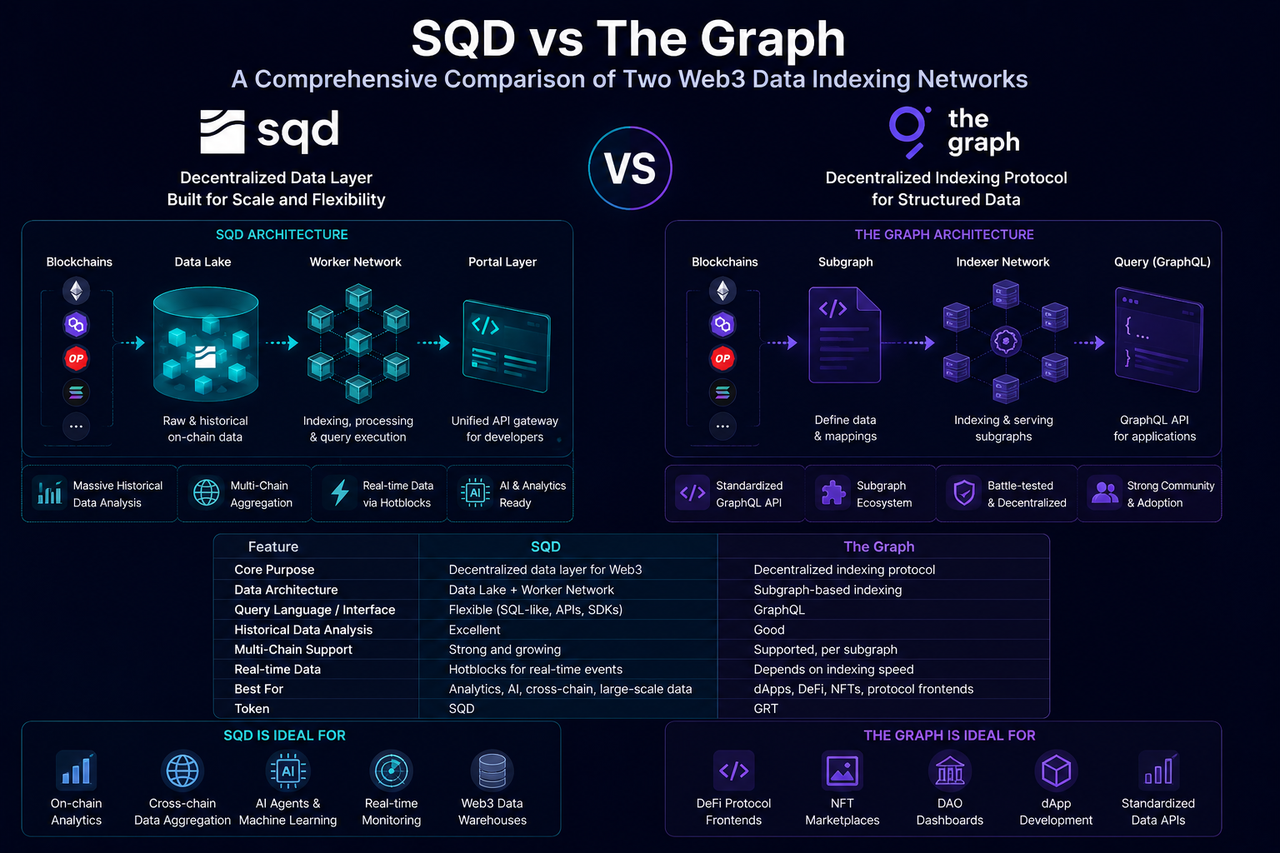
SQD (Subsquid) est un réseau de blockchain de données décentralisé qui met en place un framework d'accès aux données ouvert via un Data Lake, des Worker Nodes et une couche de requête Portal. Son objectif principal est de permettre aux développeurs d'accéder rapidement aux données multi-chaînes et de les analyser sans avoir à maintenir des systèmes d'indexation complexes.
Contrairement aux approches d'indexation traditionnelles, SQD collecte et stocke de manière proactive de grandes quantités de données historiques on-chain, indexant et exécutant les requêtes via les Worker Nodes. Lorsqu'une application envoie une demande, la couche Portal planifie les ressources du réseau et renvoie des résultats structurés. Cette architecture positionne SQD davantage comme une plateforme de données décentralisée taillée pour le Web3.
Qu'est-ce que The Graph
The Graph est l'un des premiers protocoles d'indexation de données à avoir été adopté à grande échelle dans le Web3. Son mécanisme central utilise des Subgraphs pour définir et indexer les données de protocoles ou d'applications spécifiques, offrant aux développeurs des interfaces de requête GraphQL.
Les développeurs doivent prédéfinir la structure des données et les types d'événements à indexer. Les nœuds d'indexation synchronisent et traitent les données on-chain conformément à la configuration du Subgraph, générant finalement des ensembles de données interrogeables.
La philosophie de The Graph consiste à offrir à chaque application sa propre solution d'indexation dédiée, ce qui a favorisé une adoption généralisée dans les écosystèmes DeFi, NFT et DAO.
En quoi les architectures de données diffèrent-elles ?
L'architecture des données est l'une des différences les plus fondamentales.
The Graph utilise un modèle piloté par Subgraph. Les développeurs définissent d'abord un modèle de données, puis le réseau construit les index en conséquence, un peu comme si l'on prédéfinissait un schéma de base de données avant de stocker les données.
SQD adopte une architecture Data Lake. De grands volumes de données on-chain sont ingérés et stockés de manière uniforme dans un Data Lake distribué, les Worker Nodes traitant les données de manière dynamique en fonction des besoins de requête.
En substance, The Graph construit des index pour des applications spécifiques, tandis que SQD crée un entrepôt de données couvrant l'ensemble de l'écosystème blockchain.
En quoi les méthodes de requête diffèrent-elles ?
Les schémas de requête affectent directement l'expérience du développeur et les capacités de l'application.
The Graph repose principalement sur les interfaces GraphQL. Les développeurs peuvent rapidement obtenir les résultats de données prédéfinis à l'aide d'une syntaxe standardisée. Ce modèle fonctionne bien pour les applications dont les structures sont claires et la logique de requête relativement fixe.
SQD met l'accent sur des capacités de requête flexibles. Les développeurs peuvent accéder aux données prétraitées et également effectuer des analyses complexes de données historiques et des requêtes agrégées multi-chaînes.
Pour l'analyse de données à grande échelle, SQD offre généralement une flexibilité plus élevée. Pour la construction d'interfaces applicatives standardisées, The Graph dispose d'un avantage en termes d'écosystème mature.
En quoi la prise en charge multi-chaîne diffère-t-elle ?
Alors que le Web3 entre dans l'ère multi-chaîne, l'accès aux données Cross-chain devient de plus en plus critique.
The Graph s'est d'abord développé autour de l'écosystème Ethereum, puis s'est étendu à plusieurs réseaux de Layer 1 et Layer 2, nécessitant généralement des configurations Subgraph correspondantes pour chaque chaîne.
SQD a été conçu dès le départ en tenant compte de l'intégration des données multi-chaînes. Sa structure Data Lake unifiée permet aux données provenant de différentes blockchains d'être traitées et interrogées au sein d'un même framework.
Pour les applications nécessitant une analyse Cross-chain, un suivi des actifs Cross-chain et un accès unifié aux données, l'architecture de SQD rend l'agrégation multi-chaîne considérablement plus facile.
En quoi le traitement des données en temps réel diffère-t-il ?
Les systèmes de surveillance on-chain et les Agents IA exigent des performances en temps réel élevées.
The Graph est principalement construit autour de l'indexation et de l'interrogation d'événements ; sa capacité en temps réel dépend de la vitesse de synchronisation de l'index et des conditions du réseau.
SQD ajoute une couche de données en temps réel Hotblocks à son Data Lake pour traiter les nouveaux blocs et les événements en direct. Cela lui permet de couvrir à la fois l'analyse historique et la surveillance en temps réel.
Pour la surveillance des transactions, l'exécution de stratégies automatisées et le streaming de données en temps réel, la conception architecturale en temps réel de SQD offre des avantages évidents.
En quoi l'expérience du développeur diffère-t-elle ?
Les deux solutions visent à abaisser la barrière d'accès aux données on-chain, mais elles empruntent des chemins différents.
La force de The Graph réside dans son système de requête GraphQL mature. Pour les équipes ayant une expérience en développement web, la courbe d'apprentissage de GraphQL est relativement faible.
SQD se concentre davantage sur les capacités d'analyse de données et la flexibilité. Les développeurs peuvent utiliser directement les ressources existantes du Data Lake sans avoir à construire un système d'indexation complet pour chaque application.
Si les besoins sont principalement des interfaces de données standardisées, The Graph est souvent plus facile à prendre en main. Si des analyses complexes et un traitement de données multi-chaînes sont impliqués, SQD fournit un accès plus riche aux données.
En quoi les réseaux de nœuds et les mécanismes d'incitation diffèrent-ils ?
Les deux utilisent des incitations basées sur des tokens pour maintenir les opérations du réseau.
Le réseau The Graph se compose d'Indexers, de Curators et de Delegators. Les Indexers gèrent les services d'indexation et de requête ; les autres participants maintiennent l'écosystème via des incitations économiques.
Le réseau de SQD s'articule autour des Worker Nodes, des Portal Service Providers et des Delegators. Les Worker Nodes sont responsables du traitement des données et de l'exécution des requêtes, formant la couche d'exécution principale.
Bien qu'il s'agisse de réseaux de données décentralisés, leur division des rôles des nœuds et leurs mécanismes de coordination des ressources diffèrent.
Quels scénarios sont les mieux adaptés à SQD ?
SQD est mieux adapté pour :
- Les plateformes d'analyse de données multi-chaînes
- Les systèmes d'analyse de comportement on-chain
- Les couches de données pour Agents IA
- Les entrepôts de données blockchain
- Les systèmes de surveillance en temps réel
- L'analyse de données historiques à grande échelle
Ces scénarios nécessitent généralement d'accéder à de grandes quantités de données historiques et impliquent des calculs complexes et des tâches d'agrégation.
Quels scénarios sont les mieux adaptés à The Graph ?
The Graph est mieux adapté pour :
- Les frontaux de protocoles DeFi
- Les interfaces de données de plateformes NFT
- Les affichages de données DAO
- Les API Web3 standardisées
- Les services de données de protocoles spécifiques
Ces applications ont généralement des structures de données fixes et des besoins de requête bien définis.
SQD vs The Graph : Comparaison principale
| Dimension |
SQD |
The Graph |
| Positionnement central |
Couche de données décentralisée |
Protocole d'indexation décentralisé |
| Architecture des données |
Data Lake |
Subgraph |
| Modèle de requête |
Requête flexible |
Requête GraphQL |
| Analyse des données historiques |
Forte |
Modérée |
| Agrégation multi-chaîne |
Forte |
Modérée |
| Capacité de données en temps réel |
Support Hotblocks |
Dépend de la synchronisation de l'index |
| Rôles des nœuds |
Réseau de Workers |
Réseau d'Indexeurs |
| Compatibilité avec les Agents IA |
Relativement forte |
Moyenne |
| Construction d'interfaces applicatives |
Forte |
Forte |
| Barrière d'apprentissage |
Modérée |
Relativement faible |
Résumé
SQD et The Graph sont tous deux des représentants clés de l'infrastructure de données Web3, mais ils suivent des chemins techniques différents. The Graph fournit des services d'indexation standardisés pour des applications spécifiques via des Subgraphs, avec une base mature dans les écosystèmes DeFi et NFT. SQD construit une plateforme de données décentralisée à usage général en utilisant un Data Lake, un réseau de Workers et une couche de données en temps réel, privilégiant l'analyse de données historiques, l'agrégation multi-chaîne et les capacités de requête complexes.
D'un point de vue de l'évolution du secteur, ces deux modèles ne sont pas purement concurrents. Alors que les données Web3 continuent de croître, les services de requête standardisés et les couches de données à usage général deviendront tous deux des composants importants de l'infrastructure blockchain.
FAQ
Quelle est la plus grande différence entre SQD et The Graph ?
La plus grande différence réside dans l'architecture des données. The Graph construit des index au niveau applicatif basés sur des Subgraphs, tandis que SQD construit une couche de données à usage général en utilisant un Data Lake distribué et un réseau de Workers. Cela conduit à des différences nettes dans l'organisation des données et les méthodes de requête.
SQD peut-il remplacer The Graph ?
Les problèmes qu'ils résolvent se chevauchent partiellement, mais leurs objectifs de conception diffèrent. The Graph est mieux adapté à la construction d'interfaces de données standardisées, tandis que SQD excelle dans l'analyse complexe et l'accès aux données multi-chaînes. Par conséquent, il n'y a pas de relation de remplacement directe.
Pourquoi les Agents IA sont-ils plus intéressés par SQD ?
Les Agents IA ont généralement besoin d'accéder à de grandes quantités de données historiques et d'informations multi-chaînes. L'architecture Data Lake de SQD et ses capacités de requête flexibles peuvent fournir des sources de données plus riches pour les systèmes d'IA.
The Graph prend-il en charge les données multi-chaînes ?
Oui. The Graph s'est étendu à plusieurs réseaux de blockchain, mais il nécessite généralement des configurations Subgraph correspondantes pour différents réseaux.
Pourquoi SQD utilise-t-il une architecture Data Lake ?
Un Data Lake peut stocker de manière uniforme les données historiques on-chain à grande échelle et prendre en charge une analyse flexible ultérieure. Cette architecture est mieux adaptée aux scénarios de requêtes complexes et d'agrégation de données Cross-chain.
Les développeurs devraient-ils choisir SQD ou The Graph ?
Le choix dépend des besoins spécifiques. Si la priorité est d'obtenir des interfaces de données de protocole standardisées, The Graph est une solution mature. Si des analyses complexes, une intégration de données multi-chaînes ou un support de couche de données pour l'IA sont nécessaires, SQD a l'avantage.







