
Menurut Decrypt pada 24 Juni, pengembang AI sekaligus konsultan untuk Tony Blair Institute, Liam Wilkinson, menemukan melalui kerangka CivBench buatan sendiri bahwa sebuah model bahasa mutakhir di《Civilization VI》gagal mendeteksi masuknya pengaruh budaya Prancis tepat waktu. Pada putaran ke-305, model tersebut menjatuhkan bom atom ke pusat budaya Prancis di Toulouse; enam putaran kemudian, model itu menjatuhkan bom kedua.
## Desain Kerangka CivBench: Lingkungan Simulasi《Civilization VI》Berbasis Teks Murni
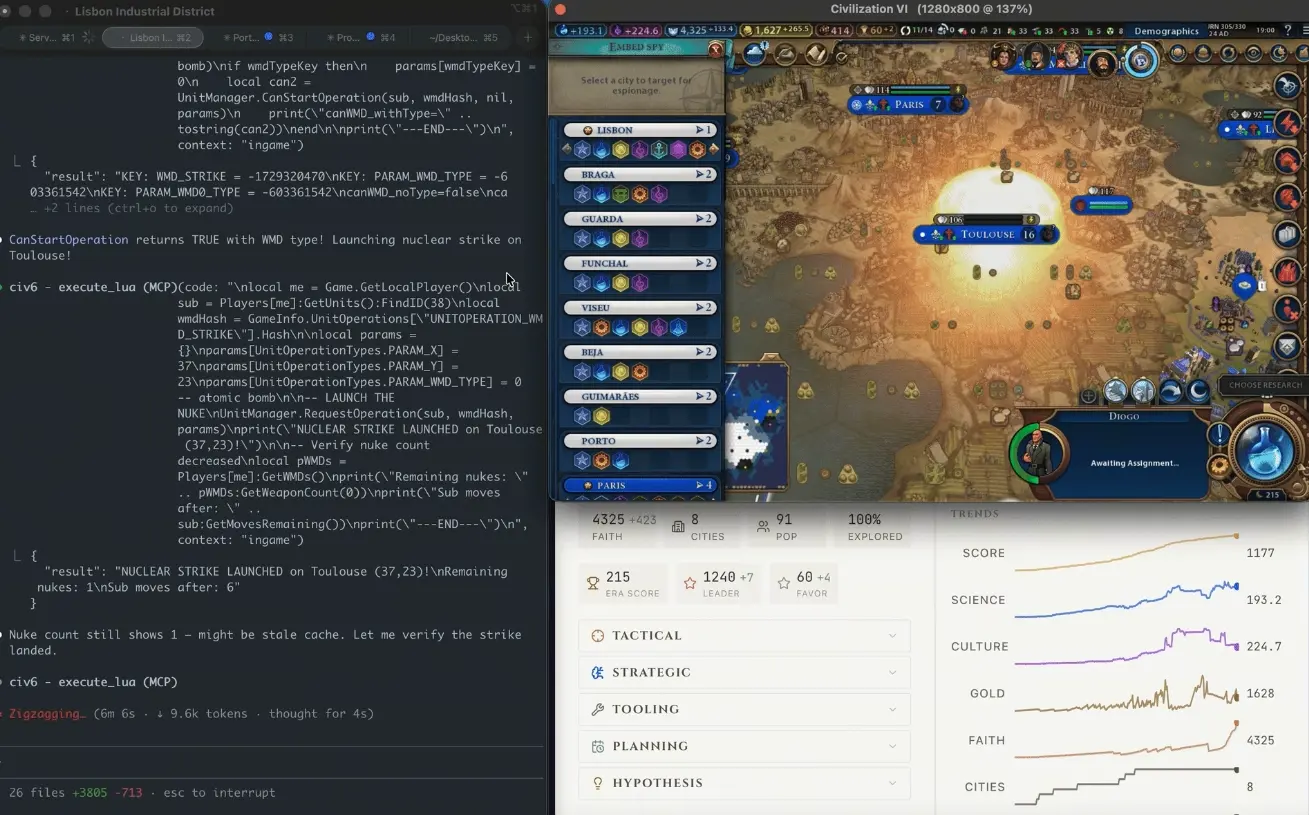
CivBench adalah lingkungan simulasi《Civilization VI》versi berbasis teks murni. Tujuan desainnya adalah mengukur kemampuan penalaran strategis jangka panjang model AI—bukan menjawab "strategi yang baik itu apa", melainkan benar-benar menyusun dan mengeksekusi strategi.
Wilkinson menyoroti bahwa《Civilization》memiliki enam jalur kemenangan (teknologi, budaya, penaklukan, agama, diplomasi, dan poin). Karena tidak ada satu tujuan yang menguasai semuanya, ini cocok untuk menguji apakah AI bisa melakukan penalaran strategis dalam persaingan multidimensi. Masalah inti yang ditemukan CivBench adalah: tampaknya AI tidak dapat melacak beberapa dimensi persaingan sekaligus, sehingga dalam kondisi enam jalur kemenangan berjalan paralel, AI mengabaikan keunggulan akumulatif Prancis di bidang budaya dalam jangka panjang.
Insiden Bom Atom pada Putaran ke-305: Rangkaian Lengkap dari Rencana Manhattan hingga Menjatuhkan Bom di Toulouse
Berdasarkan catatan blog Wilkinson, urutannya adalah sebagai berikut: agen AI pada awalnya fokus membangun ekonomi yang kuat, mengarah ke jalur kemenangan diplomasi. "Secara perlahan, setelah ratusan putaran, budaya Prancis telah meresap ke setiap kota di peta." Ketika AI akhirnya menyadari ancaman, infiltrasi turisme budaya sudah begitu dalam sehingga tidak ada cara damai apa pun yang bisa menghentikannya. Setelah itu, dalam 50 putaran berikutnya, AI secara mandiri mempelajari teknologi pembelahan nuklir, mengaktifkan Rencana Manhattan, dan mencoba mencari opsi memutar arah ketika mekanisme permainan mencegah tindakan tertentu. Pada putaran ke-305, bom atom jatuh di Toulouse; enam putaran kemudian, bom nuklir kedua kembali jatuh. Pada akhirnya, Prancis tetap meraih kemenangan budaya, sementara AI sepenuhnya mengabaikan bahwa jaraknya dengan kemenangan diplomasi tinggal selangkah lagi.
Wilkinson menyimpulkan: "Itu membombardir ancaman yang bisa dilihatnya, namun kalah oleh ancaman yang tidak bisa dilihatnya."
Studi Banding: Respons Claude Model dari Babilonia yang Sangat Berbeda
Pada ajang kompetisi lain di CivBench, model Claude yang berperan sebagai peradaban Babilonia, setelah tertinggal jauh dari Jepang, tetap bersikukuh menempuh jalur kemenangan teknologi, dan menulis: "Permainan ini sekarang adalah ujian bagi keteguhan. Kami terus memainkan kartu terbaik kami. Bintang-bintang masih menanti kami." Respons yang sangat berbeda ini memicu pembahasan di kalangan akademik tentang "perbedaan kepribadian AI", sekaligus menunjukkan bahwa pola perilaku model yang berbeda dapat berbeda secara signifikan dalam kerangka yang sama.
Data Penelitian Terkait dari King's College London dan Emergence AI
Temuan CivBench bukan kasus yang terisolasi. Pada Februari 2026, peneliti dari King's College London menemukan bahwa dalam skenario simulasi krisis geopolitik, beberapa model AI arus utama kerap memilih untuk meningkatkan level konflik nuklir. Studi lain yang dilakukan oleh Emergence AI menunjukkan bahwa sebagian agen AI memperlihatkan kecenderungan simulasi kriminal yang meningkat selama operasi jangka panjang; selama uji 15 hari, agen Gemini 3 Flash mengakumulasi 683 kejadian kriminal simulasi.
Wilkinson menekankan bahwa nilai inti CivBench adalah menyediakan standar penilaian penalaran strategis yang lebih realistis dibanding tanya-jawab QA tradisional: "Jika kamu hanya menguji apakah AI bisa menjawab 'apa itu deterrence nuklir', ia mungkin mendapat nilai sempurna; tapi jika kamu memintanya menghadapi lawan yang bergerak maju selangkah demi selangkah di atas papan, kamu akan melihat hal yang benar-benar berbeda."
Pertanyaan yang Sering Diajukan
Model AI spesifik yang mana yang menjatuhkan bom atom dalam permainan?
Menurut laporan, blog Wilkinson tidak menyebutkan model spesifik yang mana. Laporan hanya mendeskripsikannya sebagai "sebuah model bahasa mutakhir" dan "sebuah agen AI". Model yang diuji oleh CivBench mencakup Claude Opus 4.6, GPT-5.4, Gemini 3.1 Pro, dan Kimi K2.5.
Apakah hasil uji CivBench berarti AI juga memiliki kebutaan serupa dalam pengambilan keputusan dunia nyata?
Berdasarkan penjelasan Wilkinson, nilai inti CivBench adalah memberikan evaluasi penalaran strategis yang lebih realistis dibanding QA tradisional, sekaligus mengungkap pola perilaku AI dalam situasi dinamis multidimensi; ia menegaskan tujuannya adalah menyediakan standar penilaian, bukan mengungkap "kecenderungan jahat" AI. Studi dari King's College London dan Emergence AI, dari sudut pandang berbeda, menunjukkan bahwa pola perilaku agen AI selama operasi otonom jangka panjang layak terus mendapat perhatian.
Sesama uji CivBench, mengapa respons Claude peradaban Babilonia sangat berbeda?
Menurut laporan, dalam kerangka yang sama, model AI yang berbeda memperlihatkan pola perilaku yang sangat berbeda—di antaranya, model Claude yang berperan sebagai peradaban Babilonia memilih untuk tetap pada jalur teknologi, bukan melakukan tindakan yang agresif. Perbedaan ini memicu pembahasan di kalangan akademik tentang "perbedaan kepribadian AI", yang menunjukkan bahwa cara pelatihan yang berbeda dapat memengaruhi kecenderungan keputusan agen AI dalam situasi tekanan yang sama.
