Cơ bản
Giao ngay
Giao dịch tiền điện tử một cách tự do
Giao dịch ký quỹ
Tăng lợi nhuận của bạn với đòn bẩy
Chuyển đổi và Đầu tư định kỳ
0 Fees
Giao dịch bất kể khối lượng không mất phí không trượt giá
ETF
Sản phẩm ETF có thuộc tính đòn bẩy giao dịch giao ngay không cần vay không cháy tải khoản
Giao dịch trước giờ mở cửa
Giao dịch token mới trước niêm yết
Futures
Truy cập hàng trăm hợp đồng vĩnh cửu
CFD
Vàng
Một nền tảng cho tài sản truyền thống
Quyền chọn
Hot
Giao dịch với các quyền chọn kiểu Châu Âu
Tài khoản hợp nhất
Tối đa hóa hiệu quả sử dụng vốn của bạn
Giao dịch demo
Giới thiệu về Giao dịch hợp đồng tương lai
Nắm vững kỹ năng giao dịch hợp đồng từ đầu
Sự kiện tương lai
Tham gia sự kiện để nhận phần thưởng
Giao dịch demo
Sử dụng tiền ảo để trải nghiệm giao dịch không rủi ro
Launch
CandyDrop
Sưu tập kẹo để kiếm airdrop
Launchpool
Thế chấp nhanh, kiếm token mới tiềm năng
HODLer Airdrop
Nắm giữ GT và nhận được airdrop lớn miễn phí
Pre-IPOs
Mở khóa quyền truy cập đầy đủ vào các IPO cổ phiếu toàn cầu
Điểm Alpha
Giao dịch trên chuỗi và nhận airdrop
Điểm Futures
Kiếm điểm futures và nhận phần thưởng airdrop
Đầu tư
Simple Earn
Kiếm lãi từ các token nhàn rỗi
Đầu tư tự động
Đầu tư tự động một cách thường xuyên.
Sản phẩm tiền kép
Kiếm lợi nhuận từ biến động thị trường
Soft Staking
Kiếm phần thưởng với staking linh hoạt
Vay Crypto
0 Fees
Thế chấp một loại tiền điện tử để vay một loại khác
Trung tâm cho vay
Trung tâm cho vay một cửa
Khuyến mãi
AI
Gate AI
Trợ lý AI đa năng đồng hành cùng bạn
Gate AI Bot
Sử dụng Gate AI trực tiếp trong ứng dụng xã hội của bạn
GateClaw
Gate Tôm hùm xanh, mở hộp là dùng ngay
Gate for AI Agent
Hạ tầng AI, Gate MCP, Skills và CLI
Gate Skills Hub
Hơn 10.000 kỹ năng
Từ văn phòng đến giao dịch, thư viện kỹ năng một cửa giúp AI tiện lợi hơn
GateRouter
Lựa chọn thông minh từ hơn 40 mô hình AI, với 0% phí bổ sung
AI Vẫn Chưa Thể Đánh Bại Kỹ Sư Trực Sẵn: Đây Là Lý Do
Tóm tắt ngắn gọn
Các công ty AI tiếp tục giới thiệu các tác nhân kỹ sư độ tin cậy trang web tự động—AI điều tra các sự cố sản xuất thay cho con người. Datadog đã thực hiện chuẩn đánh giá thực tế trên các sự cố thực, và các mô hình AI tốt nhất hiện nay vẫn chưa thể vượt qua các kỹ sư mà chúng dự định thay thế. Chuẩn đánh giá là ARFBench (Khung Đánh Giá Lý Thuyết Giải Thích Dị Thường), một dự án hợp tác giữa Datadog và Carnegie Mellon. Được xây dựng từ 63 sự cố sản xuất thực, trích xuất từ các cuộc trò chuyện Slack của kỹ sư trong các tình huống khẩn cấp trực tiếp—750 câu hỏi trắc nghiệm bao gồm 142 chỉ số giám sát và 5,38 triệu điểm dữ liệu, mỗi câu hỏi đều được xác nhận thủ công. Không có dữ liệu tổng hợp. Không có kịch bản trong sách giáo khoa. “Các khoản thiệt hại hàng nghìn tỷ đô la mỗi năm do các sự cố hệ thống,” các nhà nghiên cứu viết. Chuẩn đánh giá kiểm tra xem AI có thể thực sự giúp thay đổi điều đó hay không.
“Dù phân tích dựa trên câu hỏi đóng vai trò trung tâm trong phản ứng sự cố, vẫn chưa rõ các mô hình nền tảng hiện đại có thể đáng tin cậy trả lời các câu hỏi dạng chuỗi thời gian mà các kỹ sư thường hỏi trong thực tế hay không,” bài báo viết. Các câu hỏi có ba cấp độ. Cấp I: Có tồn tại dị thường trong biểu đồ này không? Cấp II: Nó bắt đầu khi nào, mức độ nghiêm trọng ra sao, loại gì?
Cấp III—cấp độ khó nhất—yêu cầu suy luận chéo các chỉ số: Biểu đồ này có gây ra vấn đề trong biểu đồ kia không? Đó là nơi AI gặp khó khăn. GPT-5 chỉ đạt 47,5% điểm F1 trên các câu hỏi Cấp III, một chỉ số phạt các mô hình vì chơi trò chơi câu trả lời phổ biến nhất.
“Dù phân tích dựa trên câu hỏi đóng vai trò trung tâm trong phản ứng sự cố, vẫn chưa rõ các mô hình nền tảng hiện đại có thể đáng tin cậy trả lời các câu hỏi dạng chuỗi thời gian mà các kỹ sư thường hỏi trong thực tế hay không,” các nhà nghiên cứu viết. Các mô hình xếp hạng như thế nào GPT-5 dẫn đầu tất cả các mô hình hiện có với độ chính xác 62,7%—trong một bài kiểm tra mà đoán ngẫu nhiên đạt 24,5%. Gemini 3 Pro đạt 58,1%. Claude Opus 4.6: 54,8%. Claude Sonnet 4.5: 47,2%. Chuyên gia lĩnh vực đạt 72,7% độ chính xác. Các nhà nghiên cứu không chuyên—những người nghiên cứu chuỗi thời gian tại Datadog mà không có nhiều kinh nghiệm về khả năng quan sát—vẫn đạt 69,7%. Không mô hình AI nào vượt qua được cả hai mức cơ bản của con người.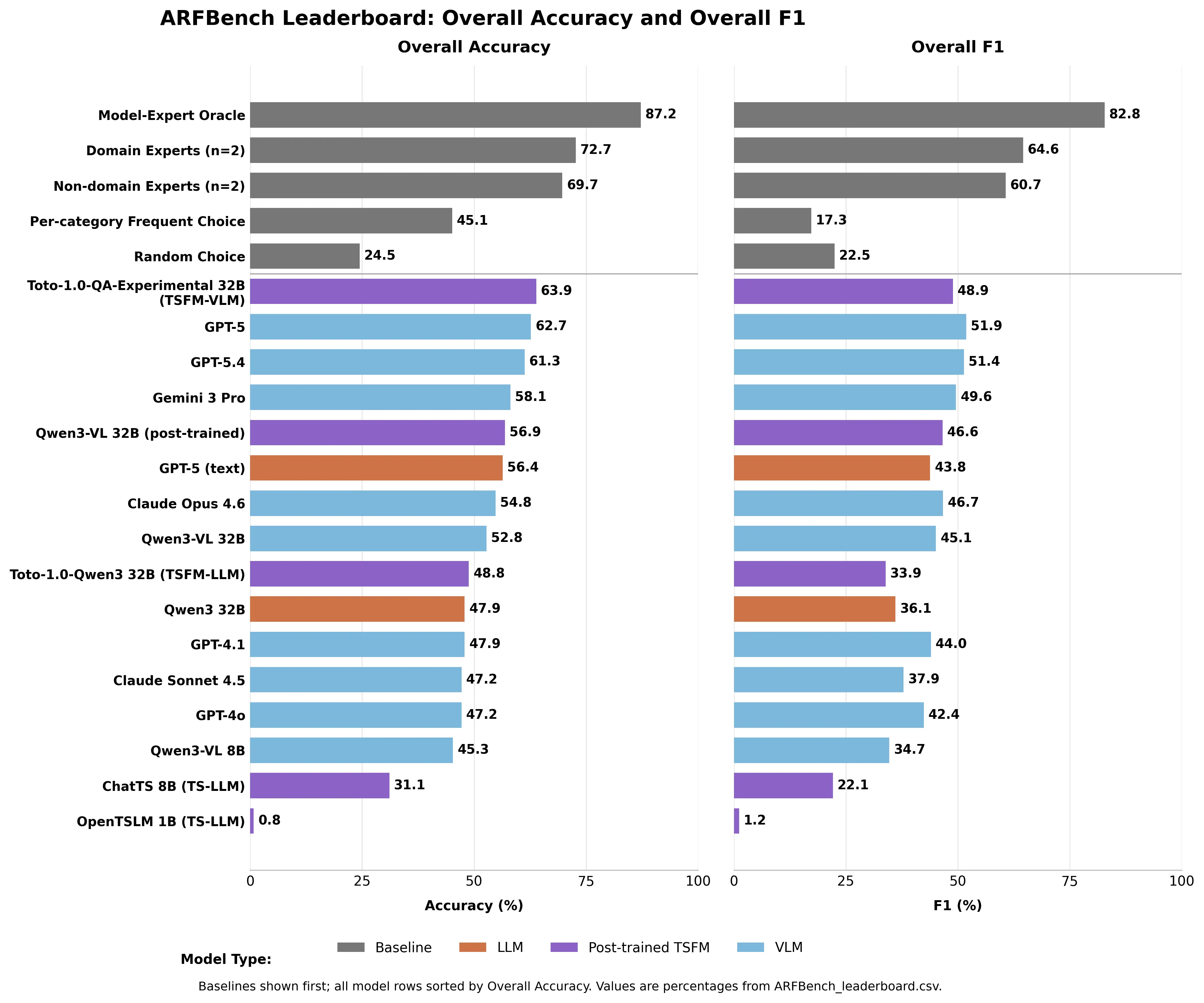
Hình ảnh do Decrypt xây dựng dựa trên file CSV bảng xếp hạng ARFBench
Mô hình thực sự đứng đầu bảng xếp hạng toàn diện là mô hình lai của Datadog: Toto—mô hình dự báo chuỗi thời gian nội bộ của họ—kết hợp với Qwen3-VL 32B. Toto-1.0-QA-Experimental đạt 63,9% độ chính xác, vượt qua GPT-5 trong khi sử dụng phần nhỏ tham số hơn. Riêng về nhận diện dị thường, nó vượt trội hơn tất cả các mô hình khác ít nhất 8,8 điểm phần trăm trong F1. Một mô hình chuyên biệt, được huấn luyện dựa trên dữ liệu khả năng quan sát, vượt trội hơn một hệ thống tổng quát tiên phong cho nhiệm vụ cụ thể này là điều dự kiến. Đó chính là mục đích. Phát hiện giá trị nhất không phải là mô hình nào đạt điểm cao nhất. “Chúng tôi quan sát các hồ sơ lỗi khác nhau rõ rệt giữa các mô hình hàng đầu và các chuyên gia con người, cho thấy rằng điểm mạnh của họ bổ sung cho nhau,” các nhà nghiên cứu viết. Các mô hình hay “ảo tưởng”, bỏ lỡ siêu dữ liệu, và mất ngữ cảnh lĩnh vực. Con người đọc sai thời gian chính xác và thỉnh thoảng thất bại trong các hướng dẫn phức tạp. Các sai sót hầu như không trùng lặp.
Hãy mô phỏng một “Giả thuyết Mô hình-Chuyên gia”—một trọng tài hoàn hảo luôn chọn đúng câu trả lời giữa AI và con người—bạn sẽ có độ chính xác 87,2% và F1 là 82,8%. Cao hơn nhiều so với từng cái riêng lẻ. Đó không phải là một sản phẩm. Đó là một mục tiêu đã được ghi nhận—được xây dựng từ các tình huống khẩn cấp thực tế, không phải dữ liệu đã qua chọn lọc—đo lường chính xác mức độ hợp tác giữa con người và AI có thể tốt hơn bao nhiêu. Bảng xếp hạng đang hoạt động trực tiếp trên Hugging Face. GPT-5 đứng ở 62,7%. Giới hạn trên là 87,2%.