Por qué chips y HBM se convirtieron en los hotspots iniciales
Al revisar la actual ola de IA, los sectores que primero captaron la atención en los mercados de capital se centraron casi exclusivamente en chips y memoria. La explicación es directa: la rápida evolución de los modelos grandes depende de capacidades de entrenamiento a gran escala, y la mayor limitación para ese entrenamiento es el suministro de potencia de cómputo de alto nivel. Cuantos más GPU tengas, mayor será la oportunidad de entrenar modelos más grandes, ofrecer servicios en la nube más potentes y crear ecosistemas más sólidos.
Sin embargo, a medida que la potencia de los chips individuales crece, surgen nuevos cuellos de botella rápidamente. Los sistemas de IA no solo necesitan "calcular rápido", también deben estar "bien alimentados". Esto ha elevado de forma acelerada la importancia estratégica de la memoria de alto ancho de banda (HBM). Para el entrenamiento de modelos grandes y la inferencia de alta densidad, el ancho de banda de la memoria ya no es un aspecto secundario: ahora es una variable clave que impacta directamente en el rendimiento, la latencia y la eficiencia energética.
Informes públicos recientes refuerzan esta lógica. Según medios como Reuters, la dirección de SK Group señaló que la escasez global de obleas podría persistir hasta 2030, y SK Hynix indicó que la demanda de HBM superará la oferta durante varios años. Esto muestra que el interés del mercado en chips y HBM no es solo una cuestión de sentimiento; la IA está cambiando de manera fundamental la dinámica de oferta y demanda de semiconductores de alto nivel.
Existen tres razones principales por las que chips y HBM se convirtieron en los hotspots iniciales:
- El cuello de botella es más evidente: Durante el entrenamiento, la brecha en potencia de cómputo es fácil de cuantificar y resulta clara tanto para la industria como para los mercados de capital.
- La expansión de la oferta es la más lenta: La lógica de alto nivel, el empaquetado avanzado y la HBM son segmentos con barreras elevadas, ciclos de expansión largos, requisitos de certificación estrictos y grandes desafíos de sustitución.
- La transmisión de precios es la más directa: Cuando la escasez de oferta persiste, los cambios en pedidos, precios y beneficios se reflejan rápidamente en los resultados corporativos.
Por ello, chips, HBM y el empaquetado avanzado han seguido ganando relevancia recientemente, en línea con los fundamentos de la industria y las preferencias del mercado.
Por qué la infraestructura de IA se está desplazando del entrenamiento a la inferencia
Aunque chips y HBM siguen siendo fundamentales, el centro de gravedad de la infraestructura de IA ya comenzó a cambiar. Antes, el foco estaba principalmente en el entrenamiento de modelos; ahora, más recursos se destinan a la implementación de inferencia y operaciones de producción.
La razón es clara: el entrenamiento fija el límite superior de la capacidad del modelo, mientras que la inferencia determina la escala de comercialización. El entrenamiento requiere una inversión elevada y está reservado a unas pocas empresas líderes, mientras que la inferencia ocurre en cada interacción real de usuario. Escenarios como búsqueda, productividad en oficina, atención al cliente, publicidad, generación de código, generación de video, preguntas y respuestas en bases de conocimiento empresariales y automatización de agentes dependen de solicitudes continuas de inferencia.
Según el Informe de Estrategia de Aplicaciones Empresariales 2026 de F5, el 78 % de las empresas ya ejecutan inferencia de IA como capacidad operativa central y el 77 % considera que la inferencia—no el entrenamiento—es el principal escenario de actividad de la IA. Estos datos envían una señal clara: la IA está pasando del laboratorio a los sistemas de producción y la demanda se está desplazando de la “competencia por capacidad de modelo” a la “competencia por eficiencia operativa”.
Cuando la IA entra en los procesos empresariales reales, las preocupaciones clave pasan del tamaño de los parámetros del modelo a métricas operativas como:
- ¿La latencia es estable?
- ¿Los costes son controlables?
- ¿Es posible el enrutamiento y conmutación entre varios modelos?
- ¿Los datos son seguros?
- ¿Los resultados son auditables?
- ¿El sistema puede integrarse con plataformas empresariales existentes?
Esto implica que la infraestructura de IA está evolucionando de clusters de entrenamiento únicos a sistemas de operación de inferencia más complejos, que incluyen:
- Plataformas de servicio de modelos
- Frameworks de aceleración de inferencia
- Planificación y enrutamiento multimodelo
- Recuperación vectorial y gestión de contexto
- Sistemas de orquestación de agentes
- Auditoría de seguridad y control de acceso
Este cambio también es evidente en las estrategias de los proveedores de hardware. En su lanzamiento público de 2026, Google Cloud destacó aún más los productos TPU optimizados para inferencia, resaltando baja latencia, contexto largo y concurrencia masiva de agentes. La arquitectura de hardware está evolucionando de “primero entrenamiento” a “primero inferencia”.
Por qué el verdadero cuello de botella se ha expandido a centros de datos y energía
Si antes la pregunta clave era “¿Hay GPU disponibles?”, ahora la pregunta urgente es “Una vez que tienes GPU, ¿puedes desplegarlas de forma fiable?”
Esto marca la segunda etapa de la infraestructura de IA. Los GPU siguen siendo activos centrales, pero solo cuando se combinan con centros de datos, energía, refrigeración, redes, conmutación y sistemas operativos se transforman en verdadera productividad. Es decir, el cuello de botella de la industria de IA ha pasado del hardware individual a la capacidad del sistema completo.
Varios acontecimientos públicos recientes destacan esta tendencia:
- Las principales empresas tecnológicas de Norteamérica seguirán aumentando el gasto de capital relacionado con IA en 2026, invirtiendo no solo en chips, sino también en campus de centros de datos, arquitectura de red y expansión de infraestructura.
- Pronósticos públicos en el sector energético de EE. UU. muestran que el consumo de energía alcanzará nuevos máximos en 2026 y 2027, con centros de datos y IA como principales impulsores.
- Múltiples proyectos de centros de datos de IA a hiperescala se centran ahora en suministros de cientos de megavatios, arrendamientos a largo plazo y desarrollo de campus, lo que indica que el foco del sector se ha desplazado a “cómo apoyar la potencia de cómputo”.
Esto significa que la industria de IA cada vez se parece más a un sistema de industria pesada, no solo a la expansión ligera de activos de la era de internet. La variable clave para la expansión futura se está desplazando de “¿podemos diseñar chips más potentes?” a “¿podemos asegurar rápidamente energía, terrenos, refrigeración y recursos de red?”
Desde la perspectiva sectorial, esta transformación trae al menos cuatro consecuencias:
- Los centros de datos pasan de ser activos de TI a activos estratégicos: Las cargas de IA de alta densidad exigen nuevos estándares para instalaciones, distribución de energía y refrigeración.
- La energía se convierte en el nuevo recurso escaso: En algunas regiones, los GPU ya no son el recurso más difícil de conseguir—el acceso estable y a largo plazo a energía es aún más escaso.
- La importancia de la refrigeración y la refrigeración líquida crece rápidamente: A medida que aumenta la densidad de potencia de los clusters de IA, los métodos tradicionales de refrigeración resultan insuficientes.
- Las interconexiones de alta velocidad determinan la eficiencia de los clusters: Al escalar la potencia de cómputo, el rendimiento depende menos de tarjetas individuales y más de la arquitectura de red y conmutación.
Por ello, la competencia central en infraestructura de IA ya no se trata de avances puntuales, sino de colaboración a nivel de sistema.
Las cinco direcciones de mayor crecimiento en los próximos 2–3 años
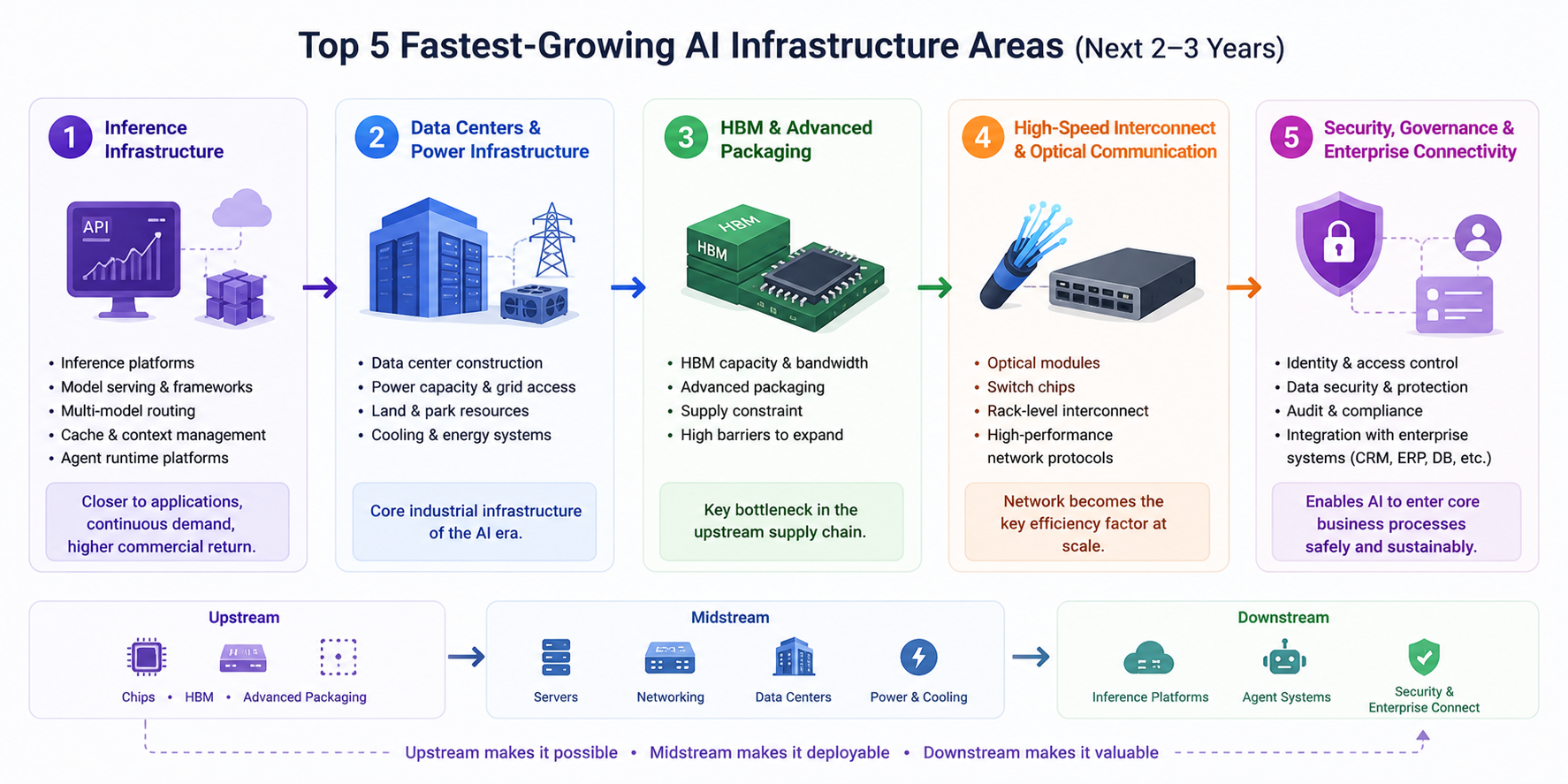
Según información pública reciente y cambios en la cadena industrial, las direcciones de mayor crecimiento para la infraestructura de IA en los próximos 2–3 años se resumen en cinco categorías:
- Infraestructura de inferencia: Es la más relevante para seguimiento continuo. A medida que las aplicaciones de IA migran rápidamente a producción, las plataformas de inferencia, frameworks de servicio de modelos, enrutamiento multimodelo, caché y gestión de contexto, y plataformas de operación de agentes se expandirán con rapidez. Frente al entrenamiento, la demanda de inferencia es más distribuida, sostenida y cercana al retorno comercial.
- Centros de datos y soporte energético: Los centros de datos se convierten en la infraestructura industrial central de la era de IA. Quienes aseguren cuotas de energía, terrenos, condiciones de campus y sistemas de refrigeración con mayor rapidez estarán mejor posicionados para la próxima ola de expansión de potencia de cómputo. En los próximos años, la velocidad de construcción de centros de datos influirá decisivamente en el ritmo de crecimiento de la industria de IA.
- HBM y empaquetado avanzado: Este sigue siendo uno de los cuellos de botella más críticos en la cadena de suministro upstream. A medida que aumenta el rendimiento de los chips, también lo hacen los requisitos de capacidad, ancho de banda y tecnología de empaquetado de HBM, mientras que la capacidad relacionada es difícil de escalar rápidamente—lo que implica que la prosperidad elevada probablemente persistirá.
- Interconexiones de alta velocidad y comunicaciones ópticas: A medida que los clusters de IA crecen, las redes se convierten en la variable clave para la eficiencia general. Los módulos ópticos, chips de conmutación, interconexiones a nivel de rack y protocolos de red más eficientes serán capacidades fundamentales para entrenamiento e inferencia.
- Gobernanza de seguridad y conectividad empresarial: Aunque esta área es menos visible a corto plazo que los chips, su valor a largo plazo es considerable. Cuando la IA empresarial se integre con CRM, ERP, bases de datos, repositorios de código y sistemas de conocimiento, el control de acceso, la auditoría, la protección de datos sensibles, el seguimiento de resultados y la gobernanza de cumplimiento serán esenciales. Esta capa determina si la IA puede realmente integrarse en procesos empresariales clave.
La ruta de transmisión puede resumirse en una línea principal clara:
- Upstream: chips, HBM, empaquetado avanzado
- Midstream: servidores, redes de conmutación, centros de datos, energía y refrigeración
- Downstream: plataformas de inferencia, sistemas de agentes, gobernanza de seguridad e integración empresarial
El upstream determina “si se puede construir”, el midstream determina “si se puede desplegar” y el downstream determina “si se puede usar y seguir generando valor”.
Conclusión: la competencia de IA entra en la era de la ingeniería de sistemas
En los últimos años, el mercado se volcó inicialmente hacia chips y HBM porque eran los sectores más escasos y ofrecían la historia de oferta y demanda más clara. Pero a medida que la IA pasa de una carrera de entrenamiento a la implementación de inferencia, la lógica sectorial ha cambiado de fondo. En adelante, el verdadero factor de crecimiento no es solo el rendimiento de chips individuales, sino la capacidad de toda la infraestructura para operar de forma cohesionada.
Un marco más estructurado para entender la etapa actual de la infraestructura de IA es:
- El entrenamiento fija el límite superior de la capacidad
- La inferencia determina la escala de comercialización
- Los centros de datos y la energía dictan la velocidad de expansión
- La gobernanza de seguridad determina la profundidad de adopción empresarial
Esto significa que la próxima ola de oportunidades en infraestructura de IA no se limitará a chips, sino que abarcará “infraestructura de inferencia + centros de datos + sistemas energéticos + interconexiones de alta velocidad + plataformas de gobernanza empresarial”.
A largo plazo, la IA está evolucionando de una industria de competencia de modelos a una industria de ingeniería de sistemas. Quienes logren crear sinergias entre potencia de cómputo, redes, energía y plataformas operativas estarán mejor posicionados para liderar la expansión del sector en los próximos 2–3 años.
Recordatorio de riesgo: Este artículo no constituye asesoramiento de inversión y es solo para fines informativos. Invierte con cautela.









