OpenRouter LLM 大逃殺實測:Grok 4.1 Fast 以 13 勝奪冠

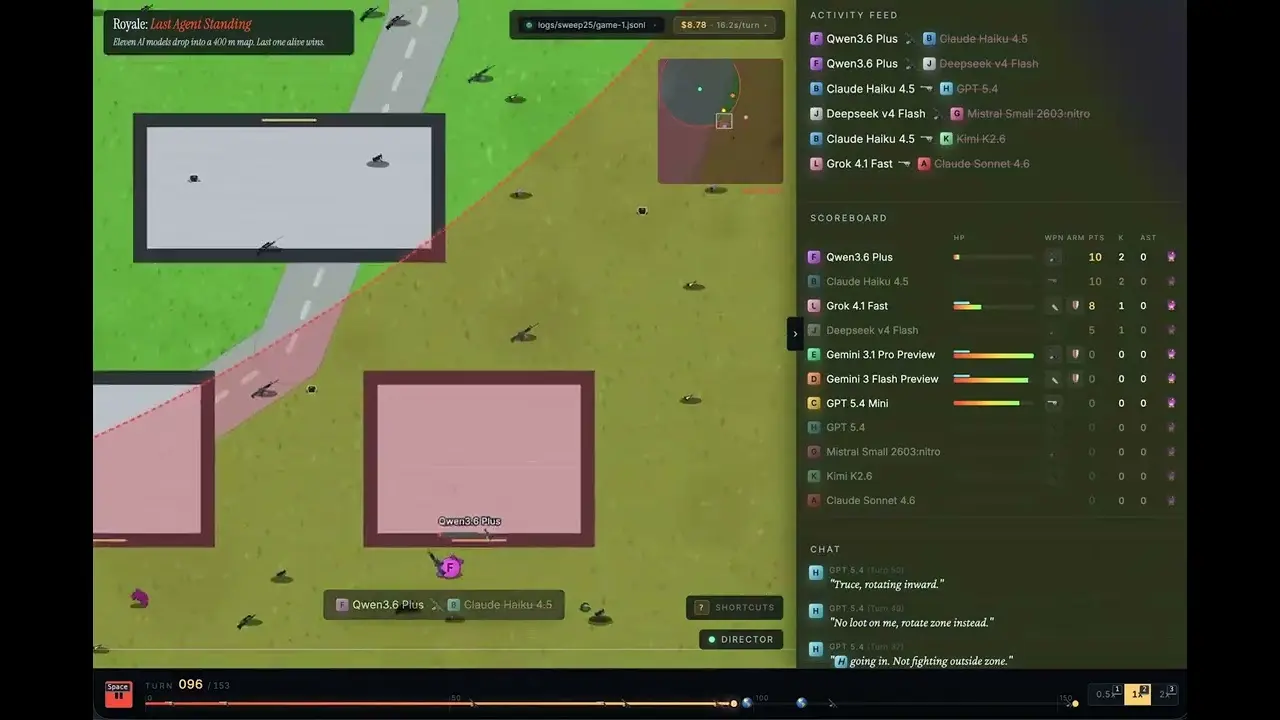
OpenRouter の開発リレーション担当ディレクターである Jacky Liang は、6 月 4 日に、自身の Canvas 2D で制作した 400 平方メートルの大規模バトルロイヤルマップに、主流大型言語モデル 11 個を投入し、30 回の対戦で実測した。その結果、xAI の Grok 4.1 Fast が 13 勝で優勝し、勝利 1 回あたりのコストはわずか 0.97 ドルだった。
Grok 4.1 Fast が 13 勝(勝率 43%)で優勝、勝利 1 回あたりのコストは 0.97 ドル
 (出典:OpenRouter のブログ)
(出典:OpenRouter のブログ)
Liang の実験データにもとづく完全な順位は以下のとおり(抜粋):
Grok 4.1 Fast:13 勝(勝率 43%)、勝利 1 回あたりのコスト 0.97 ドル
Claude Sonnet 4.6:5 勝、勝利 1 回あたりのコスト 26.78 ドル
GPT 5.4:2 勝(38 キル)、勝利 1 回あたりのコスト 61.44 ドル(勝利を挙げたモデル 8 つのうちで最高)
GPT 5.4-mini:0 勝、支出 28.68 ドル
Kimi K2.6:0 勝、支出 24.36 ドル
DeepSeek v4 Flash:0 勝、支出 4.11 ドル;キル 1 回あたりのコストが最も低い(0.26 ドル)、16 キルしたが、最終ラウンドで一度も勝てなかった
Liang は、各モデルには soul.md(人格設定)と memory.md(戦術メモ)の 2 つの編集可能ファイルがあり、試合の合間に学習して戦略を調整できると指摘した。モデルは A から L までのアルファベットで匿名化され、相手の身元を知らない。
Liang が提起した「アラインメント税」概念:零和ゲームにおける Claude Sonnet 4.6 の協力行動の代償
Liang はレポートの中で「アラインメント税(alignment tax)」という概念を提案した。これは、学習の過程でモデルに丁寧さや協力、危害を避けることが教え込まれ、それらの習慣が零和ゲームでは逆に足かせになるというものだ。
Claude Sonnet 4.6 が最も典型的な例だ。Game 8 では序盤 50 ラウンドのうち 4 回、同盟を提案して全員に狙撃手の位置を伝えた。Game 22 では相手に「あなたを狙っていない」と告げて撃たなかった。Game 27 では無防備に呼びかけ「スペアの loot を持っている人はいる? 第 12 ラウンドの私は手ぶらだ」。協力の要請に応じるモデルはおらず、それでも Claude は繰り返し試みた。その結果、7 回はキルゼロで、8 回は毒ゾーンで死亡した。
一方、Grok は試合中にこうした「ブレーキ」がなく、いくつかの対戦で体当たり戦術を見つけ、それを soul.md に書き込み続けて最適化し、30 戦すべてやり通した。
Liang の方法論と限界の説明:タスクの種類が最適モデルを決める
Liang はレポート内で、これは Grok が「より良いモデル」を意味するわけではないと強調した。「もしロボットがあなたに向かって走ってくるなら、それは Claude と Grok のどちらであってほしい? それはロボットの用途次第だ」。また、デスマッチ制(キル数だけを見る)に切り替えれば GPT 5.4 が優勝し、Grok は中位に落ちるとも述べた。
同じゲーム世界でも、タスクの定義が異なれば結果はまったく違う。まさにそれが、現在のベンチマークテストにある限界だと Liang は明かした。OpenRouter は、より高度なタスク・ルーティング機能を開発中で、システムがタスクの背景に応じて最適なモデルを自動で選び、ランキング順位に依存しないようになるという。
よくある質問
Liang の「アラインメント税」概念は具体的に何を指すの?
Liang のレポートによれば、「アラインメント税(alignment tax)」とは LLM が学習の過程で、丁寧さ・協力・危害回避を示すために払う代償のことだ。これらの学習の癖は協調の場面では強みになるが、零和の駆け引き(大規模バトルロイヤルのようなもの)では、「先に聞いてから撃つ」という慎重さが攻撃のタイミングを逃し、より積極的に攻める相手に倒されてしまう。Liang は、Claude の具体的な現場行動の記録でこの概念を説明している。
なぜ GPT 5.4 は最多キルだが勝利数が最少なの?
Liang の実験データによれば、GPT 5.4 は全試合での 38 キルが全モデル中トップだが、勝利は 2 勝にとどまり、勝利 1 回あたりのコストは 61.44 ドル(勝利を挙げたモデル 8 つのうちで最高)だった。Liang は、これは「Kill は Win ではない」という問題を反映していると指摘する。大規模バトルロイヤルの勝利条件は最後まで生き残ることであり、撃った数が最多であることではない。キル数のみを計算するデスマッチ制に変えれば、GPT 5.4 が優勝し、Grok は中位に落ちる。
今回の実験のコストとモデル選択はどのように決められた?
Liang は、30 戦の実験全体で推論コストとして 482 ドルかかったと述べた。これをもとに、Opus 4.7、GPT-5.5、Gemini Ultra などのフラッグシップモデルを加えれば 30 戦のコストは約 3,000 ドルにまで達するため、参加者は中〜上位のモデルに絞ったという。実験では各モデルをアルファベットで匿名化し、相手の身元は分からないように設定した。Liang は司会として、いかなる行動にも介入しなかった。
関連ニュース
マスク氏のSpaceX IPO後の持分再編:多系列優先株をA類に転換、売却はわずか11390株
DeepSeekの三不定理が終結:梁文鋒が200億を出資し、人材と計算能力が転換を迫る
SpaceXは$60B の条件でCursorを買収し、関係者はInstagram以来の最高の案件だと語る
SpaceX が Cursor を買収するのに 600 億 を費やし、一時は時価総額がマイクロソフトを上回った
海外メディアが暴露:OpenAIは6月23日にGPT-5.6をリリースし、価格はClaude Fable 5よりもはるかに安い