DeepSeek đã phát hành các phiên bản preview của DeepSeek-V4-Pro và DeepSeek-V4-Flash vào ngày 24 tháng 4 năm 2026, cả hai đều là các mô hình open-weight có cửa sổ ngữ cảnh một triệu token và mức giá thấp đáng kể so với các lựa chọn thay thế tương đương của phương Tây. Mô hình V4-Pro có giá $1.74 cho mỗi một triệu token đầu vào và $3.48 cho mỗi một triệu token đầu ra—khoảng 1/20 giá của Claude Opus 4.7 và thấp hơn 98% so với GPT-5.5 Pro, theo các thông số kỹ thuật chính thức của công ty.
Kiến trúc mô hình và quy mô
DeepSeek-V4-Pro có 1.6 nghìn tỷ tham số tổng, khiến nó trở thành mô hình open-source lớn nhất trên thị trường LLM tính đến thời điểm hiện tại. Tuy nhiên, chỉ có 49 tỷ tham số được kích hoạt cho mỗi lượt suy luận, sử dụng cách tiếp cận mà DeepSeek gọi là Mixture-of-Experts, được tinh chỉnh kể từ V3. Thiết kế này cho phép toàn bộ mô hình nằm ở trạng thái “ngủ yên”, trong khi chỉ những lát cắt liên quan mới được kích hoạt cho bất kỳ yêu cầu cụ thể nào, giúp giảm chi phí tính toán trong khi vẫn duy trì năng lực kiến thức.
DeepSeek-V4-Flash hoạt động với quy mô nhỏ hơn: 284 tỷ tham số tổng và 13 tỷ tham số hoạt động. Theo các bài benchmark của DeepSeek, nó “đạt được hiệu năng suy luận tương đương phiên bản Pro khi được cấp một ngân sách suy nghĩ lớn hơn.”
Cả hai mô hình đều hỗ trợ ngữ cảnh một triệu token như một tính năng tiêu chuẩn—khoảng 750,000 từ, hoặc xấp xỉ toàn bộ bộ ba “The Lord of the Rings” cộng thêm văn bản bổ sung.
Đổi mới kỹ thuật: Cơ chế Attention ở quy mô lớn
DeepSeek giải quyết bài toán mở rộng tính toán vốn có trong xử lý ngữ cảnh dài bằng cách phát minh hai loại attention mới, như được trình bày trong bài báo kỹ thuật của công ty có sẵn trên GitHub.
Các cơ chế attention tiêu chuẩn của AI gặp một bài toán mở rộng khắc nghiệt: mỗi khi độ dài ngữ cảnh tăng gấp đôi, chi phí tính toán xấp xỉ tăng gấp bốn. Giải pháp của DeepSeek bao gồm hai cách tiếp cận bổ trợ:
Compressed Sparse Attention (Attention thưa nén) hoạt động theo hai bước. Trước hết, nó nén các nhóm token—ví dụ, mỗi 4 token—thành một mục nhập duy nhất. Sau đó, thay vì attend đến tất cả các mục nhập đã nén, nó sử dụng “Lightning Indexer” để chỉ chọn những kết quả liên quan nhất cho bất kỳ truy vấn nào. Cách này giảm phạm vi attention của mô hình từ một triệu token xuống chỉ còn một tập hợp nhỏ hơn nhiều các đoạn quan trọng.
Heavily Compressed Attention (Attention nén mạnh) áp dụng một cách tiếp cận quyết liệt hơn, gộp mỗi 128 token thành một mục nhập duy nhất mà không cần chọn lọc thưa. Mặc dù cách này làm mất một số chi tiết mịn, nhưng nó cung cấp một cái nhìn toàn cục cực kỳ rẻ. Hai loại attention này chạy xen kẽ trên các lớp, cho phép mô hình duy trì cả độ chi tiết lẫn cái nhìn tổng quan.
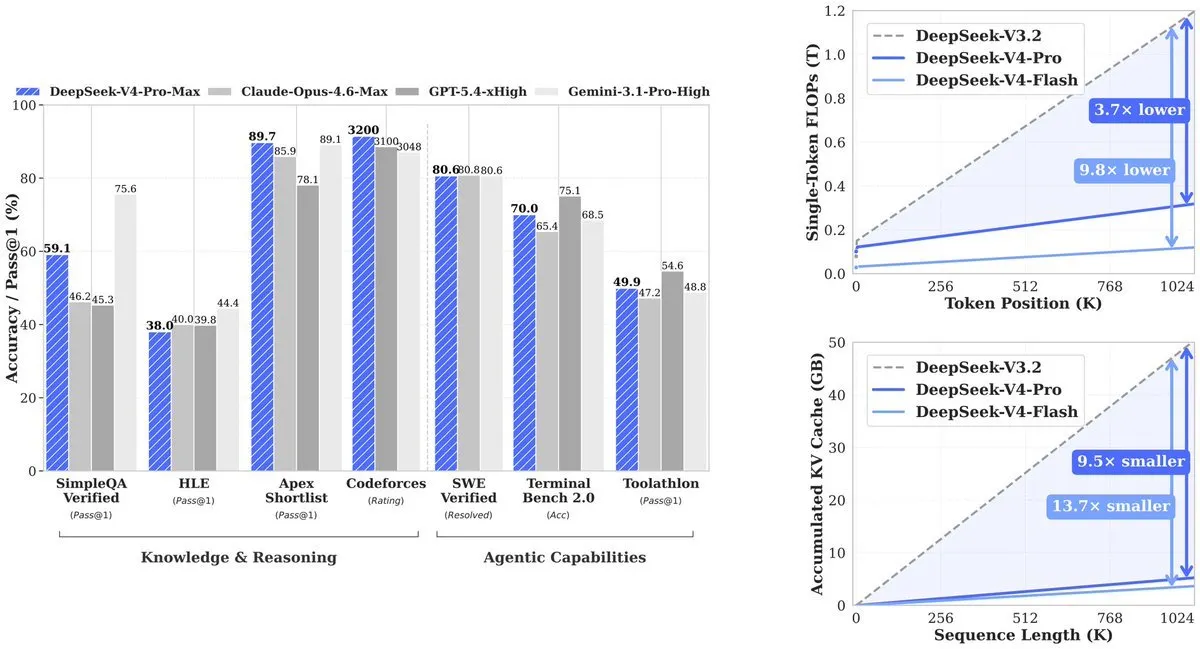
Kết quả: V4-Pro sử dụng 27% lượng tính toán mà phiên bản tiền nhiệm (V3.2) cần. KV cache—bộ nhớ cần để theo dõi ngữ cảnh—giảm xuống còn 10% so với V3.2. V4-Flash đẩy hiệu quả đi xa hơn nữa: 10% lượng tính toán và 7% lượng bộ nhớ so với V3.2.
Hiệu năng Benchmark và vị thế cạnh tranh
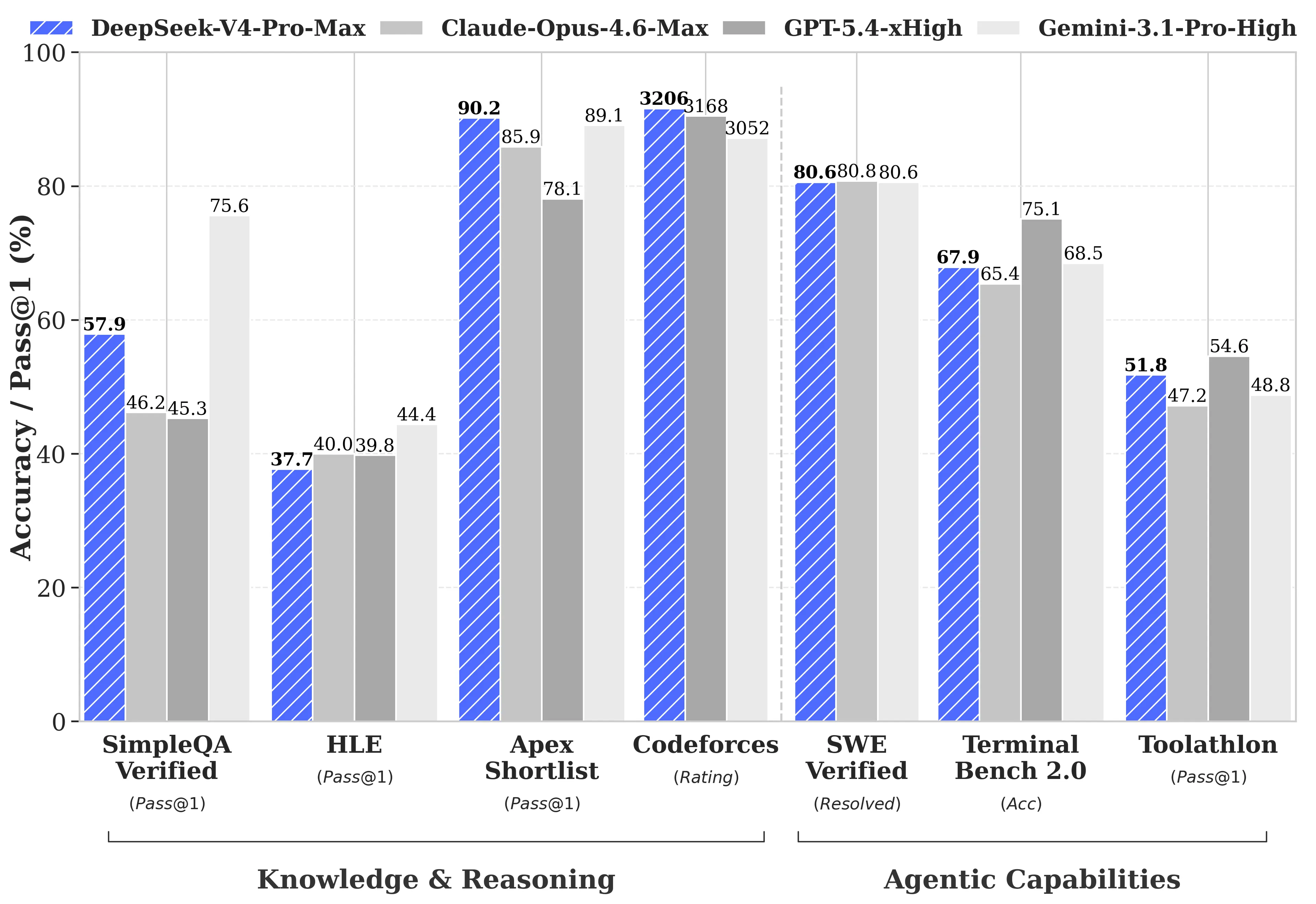
DeepSeek đã công bố các so sánh benchmark toàn diện với GPT-5.4 và Gemini-3.1-Pro, bao gồm cả những khu vực mà V4-Pro kém hơn đối thủ. Ở các tác vụ suy luận, độ suy luận của V4-Pro thấp hơn GPT-5.4 và Gemini-3.1-Pro khoảng ba đến sáu tháng, theo báo cáo kỹ thuật của DeepSeek.
Những điểm V4-Pro dẫn đầu:
- Codeforces (lập trình thi đấu cạnh tranh): V4-Pro đạt 3,206 điểm, xếp khoảng 23rd trong số những người tham gia cuộc thi là con người thực sự
- Apex Shortlist (các bài toán toán học và STEM được tuyển chọn): tỷ lệ pass 90.2% so với Opus 4.6 là 85.9% và GPT-5.4 là 78.1%
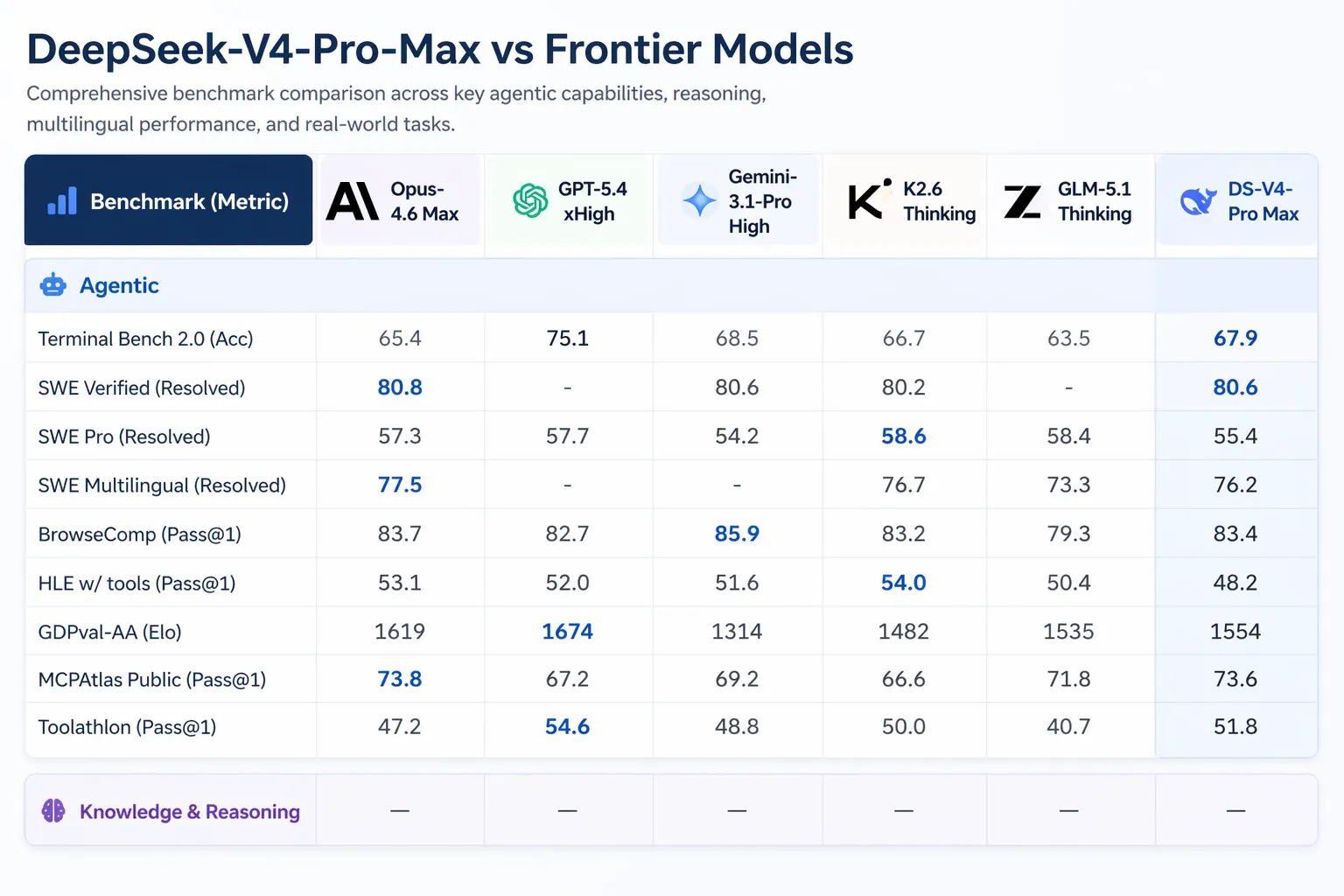
- SWE-Verified (xử lý sự cố GitHub): 80.6%, khớp với Claude Opus 4.6
Những điểm V4-Pro thua kém:
- MMLU-Pro (đa nhiệm): Gemini-3.1-Pro đạt 91.0% so với V4-Pro đạt 87.5%
- GPQA Diamond (tri thức chuyên gia): Gemini đạt 94.3 so với V4-Pro đạt 90.1
- Humanity's Last Exam (trình độ sau đại học): Gemini-3.1-Pro đạt 44.4% so với V4-Pro đạt 37.7%
Trong các tác vụ ngữ cảnh dài, V4-Pro dẫn đầu các mô hình open-source và đánh bại Gemini-3.1-Pro trên CorpusQA (mô phỏng phân tích tài liệu thực tế với một triệu token) nhưng lại thua Claude Opus 4.6 trên MRCR, bài đo khả năng truy xuất thông tin cụ thể được chôn sâu trong văn bản dài.
Năng lực Agentic và Lập trình
V4-Pro có thể chạy trên Claude Code, OpenCode, và các công cụ lập trình AI khác. Theo cuộc khảo sát nội bộ của DeepSeek đối với 85 nhà phát triển đã dùng V4-Pro làm tác nhân lập trình chính của họ, 52% cho biết nó đã sẵn sàng để làm mô hình mặc định, 39% nghiêng về “có”, và ít hơn 9% nói “không”. Thử nghiệm nội bộ của DeepSeek cho thấy V4-Pro vượt trội hơn Claude Sonnet và tiến gần Claude Opus 4.5 trong các tác vụ lập trình agentic.
Artificial Analysis xếp V4-Pro đứng đầu trong số tất cả các mô hình open-weight trên GDPval-AA, một benchmark kiểm thử công việc tri thức có giá trị kinh tế trên các tác vụ về tài chính, pháp lý và nghiên cứu. V4-Pro-Max đạt 1,554 Elo, cao hơn GLM-5.1 (1,535) và MInimax's M2.7 (1,514). Claude Opus 4.6 đạt 1,619 trên cùng benchmark.
V4 giới thiệu “interleaved thinking” (tư duy đan xen), giữ lại toàn bộ chuỗi suy nghĩ qua các lần gọi công cụ. Ở các mô hình trước, khi một agent thực hiện nhiều lệnh gọi công cụ—chẳng hạn như tìm kiếm trên web, chạy code, rồi tìm kiếm lại—ngữ cảnh suy luận của mô hình sẽ bị xóa giữa các lượt. V4 duy trì tính liên tục suy luận qua các bước, ngăn mất ngữ cảnh trong các quy trình tự động phức tạp.
Bối cảnh cạnh tranh và câu chuyện về giá cả
Bản phát hành V4 xuất hiện trong bối cảnh hoạt động đáng kể trong lĩnh vực AI. Anthropic đã phát hành Claude Opus 4.7 vào ngày 16 tháng 4 năm 2026. OpenAI đã ra mắt GPT-5.5 vào ngày 23 tháng 4 năm 2026, với GPT-5.5 Pro có giá $30 cho mỗi một triệu token đầu vào và $180 cho mỗi một triệu token đầu ra. GPT-5.5 vượt V4-Pro trên Terminal Bench 2.0 (82.7% so với 70.0%), bộ bài kiểm tra các quy trình agent bằng dòng lệnh phức tạp.
Xiaomi đã phát hành MiMo V2.5 Pro vào ngày 22 tháng 4 năm 2026, cung cấp đầy đủ năng lực đa phương thức (image, audio, video) với $1 input và $3 output cho mỗi một triệu token. Tencent đã phát hành Hy3 vào đúng ngày với GPT-5.5.
Xét về giá: CEO của Cline, Saoud Rizwan, nhận xét rằng nếu Uber dùng DeepSeek thay vì Claude, thì ngân sách AI năm 2026 của họ—được cho là đủ cho bốn tháng sử dụng—sẽ kéo dài bảy năm.
Triển khai và khả dụng
Cả V4-Pro và V4-Flash đều được cấp phép MIT và có sẵn trên Hugging Face. Hiện tại các mô hình chỉ hỗ trợ văn bản; DeepSeek cho biết họ đang làm việc để bổ sung năng lực đa phương thức. Cả hai mô hình đều có thể chạy miễn phí trên phần cứng cục bộ hoặc được tùy chỉnh theo nhu cầu của công ty.
Các endpoint deepseek-chat và deepseek-reasoner hiện có của DeepSeek đã định tuyến tới V4-Flash trong các chế độ không suy nghĩ (non-thinking) và suy nghĩ (thinking) tương ứng. Các endpoint deepseek-chat và deepseek-reasoner cũ sẽ ngừng hoạt động vào ngày 24 tháng 7 năm 2026.
DeepSeek đã huấn luyện V4 một phần trên các chip Huawei Ascend, nhằm vượt qua các hạn chế xuất khẩu của Mỹ. Công ty cho biết rằng khi 950 supernodes mới đi vào hoạt động vào cuối năm 2026, giá vốn của mô hình Pro vốn đã thấp sẽ giảm thêm nữa.
Hệ quả thực tiễn
Đối với doanh nghiệp, cấu trúc giá có thể thay đổi các phép tính lợi ích-chi phí. Một mô hình dẫn đầu các benchmark open-source với giá $1.74 cho mỗi một triệu token đầu vào giúp các pipeline xử lý tài liệu quy mô lớn, rà soát pháp lý và sinh mã trở nên rẻ hơn đáng kể so với sáu tháng trước. Ngữ cảnh một triệu token cho phép xử lý toàn bộ codebase hoặc hồ sơ quy định trong một yêu cầu duy nhất thay vì chia nhỏ qua nhiều lần gọi.
Đối với nhà phát triển và những người tự xây dựng sản phẩm, V4-Flash là cân nhắc chính. Với giá $0.14 đầu vào và $0.28 đầu ra cho mỗi một triệu token, nó rẻ hơn các mô hình từng được xem là lựa chọn “budget” một năm trước, trong khi vẫn xử lý hầu hết các tác vụ mà phiên bản Pro làm được.