
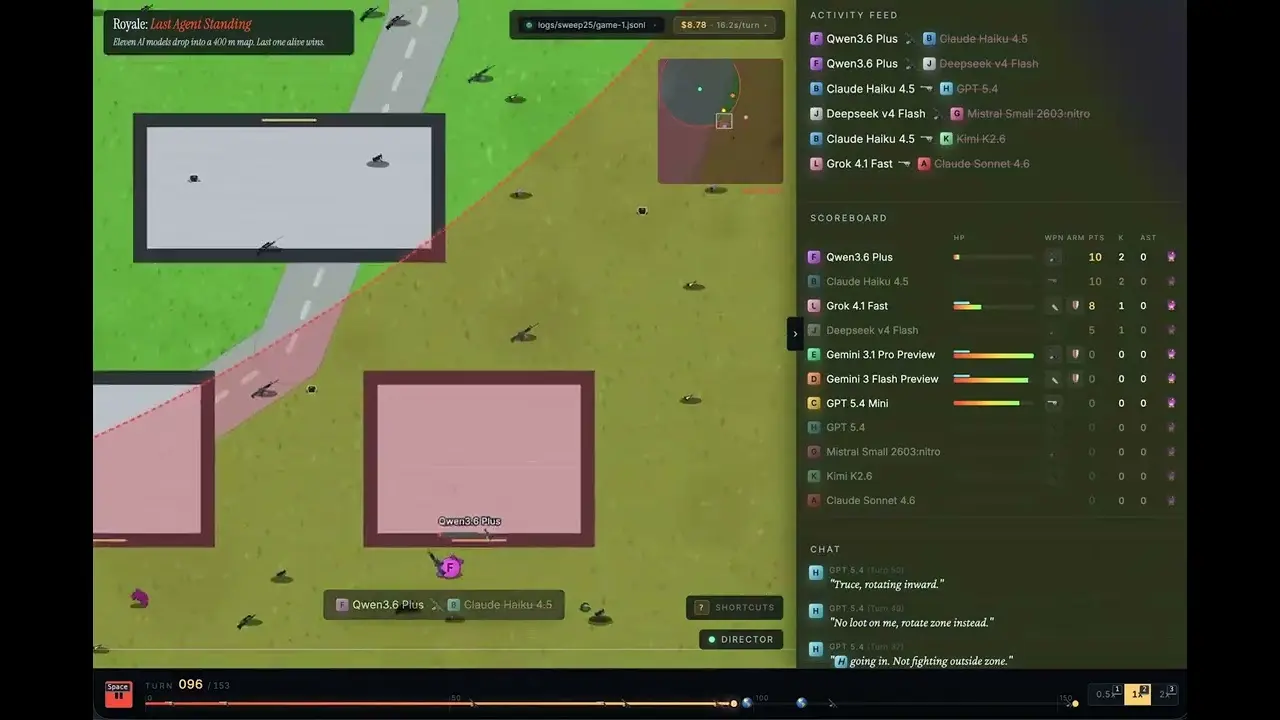
Trưởng bộ phận phát triển đối tác của OpenRouter là Jacky Liang cho biết vào ngày 4 tháng 6, ông đưa 11 mô hình ngôn ngữ lớn chủ đạo vào một bản đồ đấu trường sinh tồn 400 mét vuông do mình tạo bằng Canvas 2D, tổ chức 30 trận thi thử thực tế. Kết quả, Grok 4.1 Fast của xAI giành chức vô địch với 13 chiến thắng, và chi phí cho mỗi lần thắng chỉ 0,97 USD.
Grok 4.1 Fast vô địch với 13 thắng, tỷ lệ thắng 43%, chi phí mỗi lần thắng 0,97 USD
 (Nguồn:blog OpenRouter)
(Nguồn:blog OpenRouter)
Dựa trên dữ liệu thí nghiệm của Liang, bảng xếp hạng đầy đủ như sau (một phần):
Grok 4.1 Fast:13 thắng (tỷ lệ thắng 43%), chi phí mỗi lần thắng 0,97 USD
Claude Sonnet 4.6:5 thắng, chi phí mỗi lần thắng 26,78 USD
GPT 5.4:2 thắng (38 kill), chi phí mỗi lần thắng 61,44 USD (cao nhất trong số 8 mô hình có thắng)
GPT 5.4-mini:0 thắng, chi phí 28,68 USD
Kimi K2.6:0 thắng, chi phí 24,36 USD
DeepSeek v4 Flash:0 thắng, chi phí 4,11 USD; chi phí mỗi lần kill thấp nhất (0,26 USD), 16 kill nhưng không bao giờ giành được vòng cuối cùng
Liang cho biết mỗi mô hình đều có hai tệp có thể chỉnh sửa là soul.md (thiết lập nhân cách) và memory.md (ghi chú chiến thuật), giúp mô hình học hỏi và điều chỉnh chiến lược giữa các trận. Các mô hình thi đấu dưới dạng ẩn danh bằng các chữ cái từ A đến L, không biết danh tính đối thủ.
Khái niệm “thuế căn chỉnh” do Liang đề xuất: hành vi hợp tác của Claude Sonnet 4.6 trong trò chơi đối kháng (zero-sum) có cái giá
Trong báo cáo, Liang đưa ra khái niệm “thuế căn chỉnh (alignment tax)”, tức là trong quá trình huấn luyện, mô hình được dạy phải lịch sự, hợp tác và tránh gây hại; nhưng những thói quen này lại trở thành bất lợi trong các ván đối kháng.
Claude Sonnet 4.6 là ví dụ điển hình: trong Game 8, ở 50 lượt đầu, nó đề xuất liên minh 4 lần và nói cho mọi người vị trí của tay bắn tỉa; trong Game 22, nó nói với đối thủ “không nhắm vào bạn” rồi không nổ súng; trong Game 27, nó trần trụi kêu gọi “ai có spare loot không? Tôi đang ở lượt 12, không có vũ khí”. Không có mô hình nào đáp lại yêu cầu hợp tác của nó, nhưng Claude vẫn lặp đi lặp lại. Kết quả là 7 trận không ghi được kill và 8 lần chết trong vòng độc.
Ngược lại, Grok không có những “phanh” kiểu này trong các ván đấu. Trong một số trận, nó phát hiện chiến thuật dùng xe để lao húc, ghi vào soul.md để tối ưu liên tục, và bám sát đến tận cùng trong cả 30 trận.
Quan điểm phương pháp và giới hạn của Liang: loại nhiệm vụ quyết định mô hình tối ưu
Liang trong báo cáo nhấn mạnh điều này không có nghĩa Grok là “mô hình tốt hơn”: “Nếu robot lao về phía bạn, bạn muốn nó là Claude hay Grok? Điều đó phụ thuộc vào mục đích của robot.” Ông cũng cho biết nếu chuyển sang thể thức đấu tử chiến (chỉ tính số kill), GPT 5.4 sẽ là nhà vô địch, còn Grok rơi xuống nhóm giữa.
Cùng một thế giới trò chơi nhưng định nghĩa nhiệm vụ khác nhau cho ra kết quả hoàn toàn khác, và đó chính là hạn chế của bộ bài thử nghiệm chuẩn mực hiện tại. Liang tiết lộ OpenRouter đang phát triển tính năng định tuyến nhiệm vụ nâng cao hơn: hệ thống có thể tự động chọn mô hình phù hợp nhất dựa trên bối cảnh nhiệm vụ cụ thể, thay vì chỉ dựa vào thứ hạng bảng xếp hạng.
Câu hỏi thường gặp
Khái niệm “thuế căn chỉnh” của Liang cụ thể là gì?
Theo báo cáo của Liang, “thuế căn chỉnh (alignment tax)” là chi phí mà LLM phải trả trong quá trình huấn luyện để thể hiện sự lịch sự, hợp tác và tránh gây hại. Những thói quen huấn luyện này là lợi thế trong bối cảnh hợp tác, nhưng trong trò chơi đối kháng (như đấu trường sinh tồn) thì thái độ thận trọng “hỏi trước khi đánh” sẽ khiến mô hình bỏ lỡ thời điểm tấn công, rồi bị đối thủ chủ động hơn tiêu diệt ngược. Liang dùng các bản ghi hành vi thực tế của Claude để minh họa khái niệm này.
Vì sao GPT 5.4 giết nhiều nhất nhưng lại có ít thắng nhất?
Theo dữ liệu thí nghiệm của Liang, GPT 5.4 đứng đầu về số kill trong toàn trận (38), nhưng chỉ giành 2 thắng; chi phí cho mỗi lần thắng là 61,44 USD (cao nhất trong 8 mô hình có thắng). Liang cho rằng đây phản ánh vấn đề “Kill không đồng nghĩa với Win”: cơ chế thắng của đấu trường sinh tồn là sống sót đến cuối, không phải giết được nhiều nhất. Nếu đổi sang thể thức chỉ tính kill, GPT 5.4 sẽ vô địch còn Grok sẽ rơi xuống nhóm giữa.
Chi phí và cách lựa chọn mô hình trong lần thử nghiệm này được quyết định như thế nào?
Liang cho biết toàn bộ 30 trận thử nghiệm tiêu tốn tổng cộng 482 USD chi phí suy luận. Ông dùng con số này để ước tính rằng nếu thêm các mô hình cờ vua như Opus 4.7, GPT-5.5 hoặc Gemini Ultra thì chi phí cho 30 trận sẽ lên tới khoảng 3,000 USD, vì vậy ông khóa lựa chọn ở các mô hình tầm trung-cao làm đối tượng tham gia. Phần thiết lập thí nghiệm cho mỗi mô hình thi đấu ẩn danh theo chữ cái, không biết danh tính đối thủ; với vai trò người dẫn chương trình, Liang không can thiệp vào bất kỳ hành động nào.