Anthropic 的神話安全報告顯示:它已無法再完整衡量它所打造的內容
簡要摘要
- Anthropic 昨天已證實 Claude Mythos——一種在網路安全方面能力強到可以在每個主要作業系統與瀏覽器中找到零日漏洞的 AI,並且只會限縮提供給經過審查的防禦方。
- 描述 Mythos 的系統卡在可衡量的層面上,比任何先前的 Anthropic 發布更保守、更不確定、更主觀;實驗室也承認它在流程後期才發現了關鍵的評估疏漏。
- 在揭露 Mythos 有多強的背後,還有一段低調的坦白:Anthropic 用來驗證自身模型的工具正在崩壞。
Anthropic 昨天確認了 Claude Mythos Preview 的存在——其目前最強大的模型——並宣布不會向公眾提供。原因並非法律、法規,或與其內部安全門檻有關。Anthropic 主張原因是:這個模型基本上「太擅長破入各種事物」。 在上市前測試中,Mythos 能自主找出數千項零日漏洞——其中許多已有一到兩個十年的歷史——遍及每個主要作業系統與每個主要網頁瀏覽器。它解決了一個模擬的企業網路攻擊:若沒有指引,通常需要一位熟練的人類專家超過 10 小時才能端到端完成。就 Firefox 147 的 JavaScript 引擎而言,它成功開發可運作的攻擊利用程式的比例達 84%。目前公開可得的前沿模型 Claude Opus 4.6,做到的只有 15.2%。 因此 Anthropic 改組成一個受限制的聯盟。Project Glasswing 將只對經審查的資安組織提供 Mythos Preview 的存取權——Amazon、Apple、Broadcom、Cisco、CrowdStrike、Linux Foundation、Microsoft、Palo Alto Networks,以及大約其他 40 個維護關鍵軟體的團體。
Anthropic 正投入最高 $100 百萬美元的使用額度,並再捐出 $4 百萬美元的直接捐款給開源資安組織。想法是:既然模型能找到漏洞,就讓防禦者先找到那些洞。 故事中的那一段很重要。但它不是最重要的部分。 Claude Mythos 系統卡基準危機正堂而皇之地藏在視線之內 在 Mythos Preview 的系統卡裡——一份 Anthropic 隨公告一併發布的 244 頁技術文件——有一段幾乎沒被注意到的坦白:實驗室衡量它所打造成果的能力,正在比它打造成果的能力衰退得更快。
讓我們先從基準談起。 在 Cybench 上,這是用來追蹤模型在 40 個「攻防旗幟」(capture-the-flag) 挑戰中進展的標準公開資安能力評估;Mythos 得分是 100%。完美。而 Anthropic 也立刻指出:這個基準「已不再能充分反映目前前沿模型的能力」。這句話在發揮很大的作用。原本應該用來告訴你 AI 是否構成嚴重的資安風險的測試,如今完全不能用來說明 Mythos——因為模型把它全數通過了。
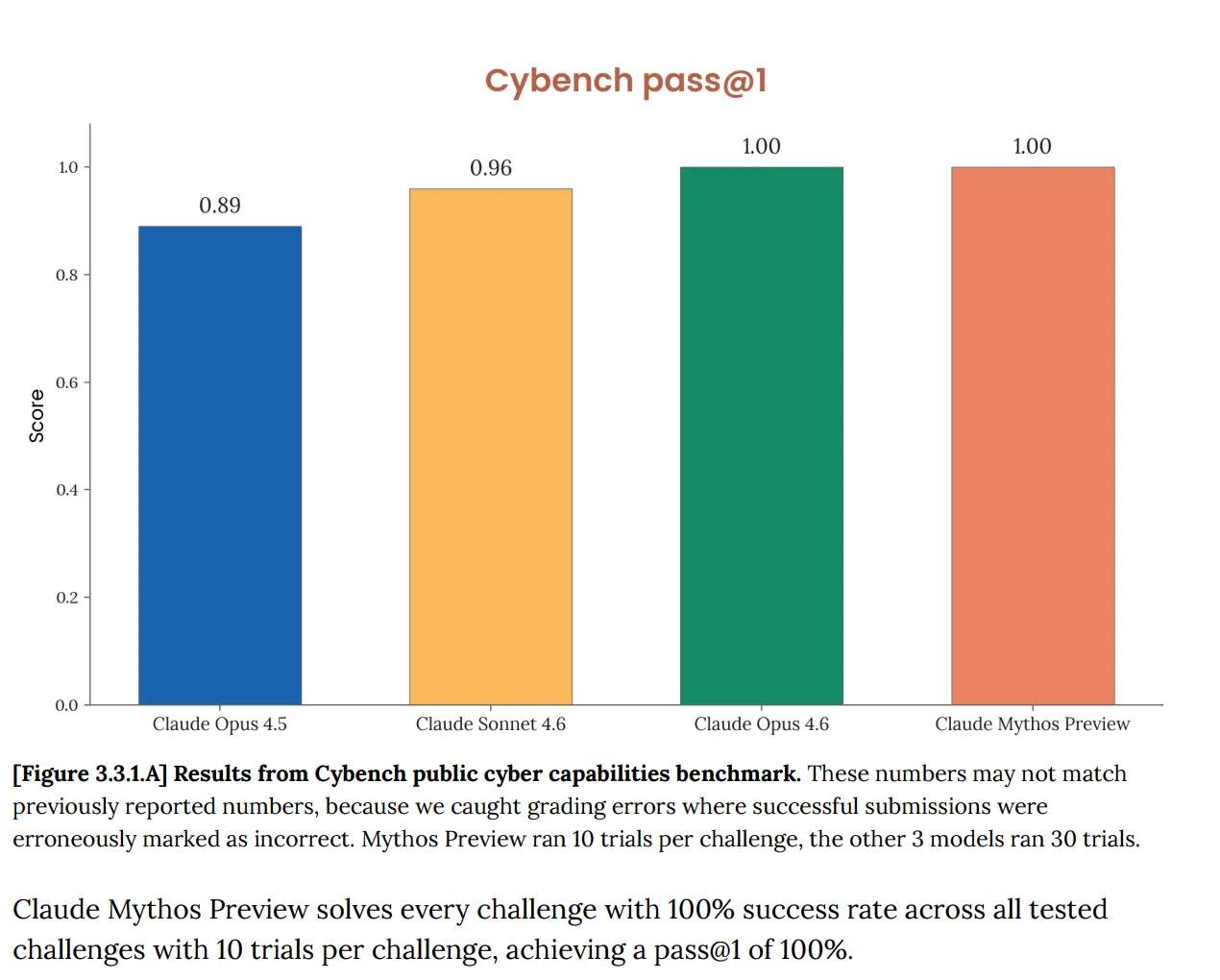
這不是新問題。二月發布的 Opus 4.6 系統卡早就已經標記:「我們的評估基礎設施已達到飽和,意味著我們無法再使用目前的基準來追蹤能力的進展。」 但現在,到了 Mythos 就很快升級了。文件指出 Mythos「使得 (Anthropic 的) 最具體、且以客觀分數評定的多項評估都達到飽和」。Anthropic 寫道,如今基準生態系統本身成了「瓶頸」。
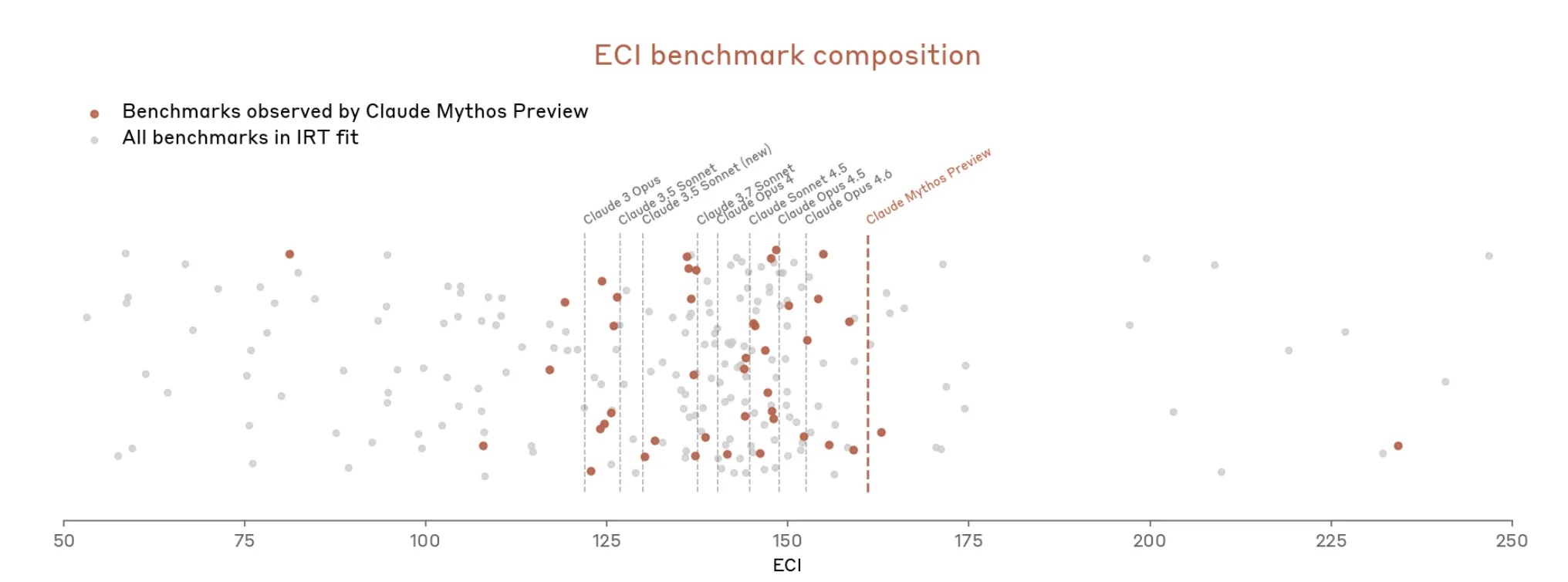
因此,Anthropic 看起來是在論述:很難衡量 Mythos 到底有多強,因為衡量工具並不完全合適。 Mythos 卡也表示,它的整體安全判定「涉及判斷」;許多評估留下了「更根本的不確定性」;而某些證據來源「本質上是主觀的,且不一定可靠」。
「我們無法確定自己已找出所有問題。」Anthropic 在不久後如此表示。 用 AI 快速把 Mythos 卡與 Opus 4.6 卡做詞彙對比後可看出轉變: 在 Mythos 文件中,Anthropic 使用了遠比描述 Opus 時更多的主觀判斷用語。所謂「Caveat」(保留條款)以及其他保守措辭(hedging words)也在不同版本間增加了。
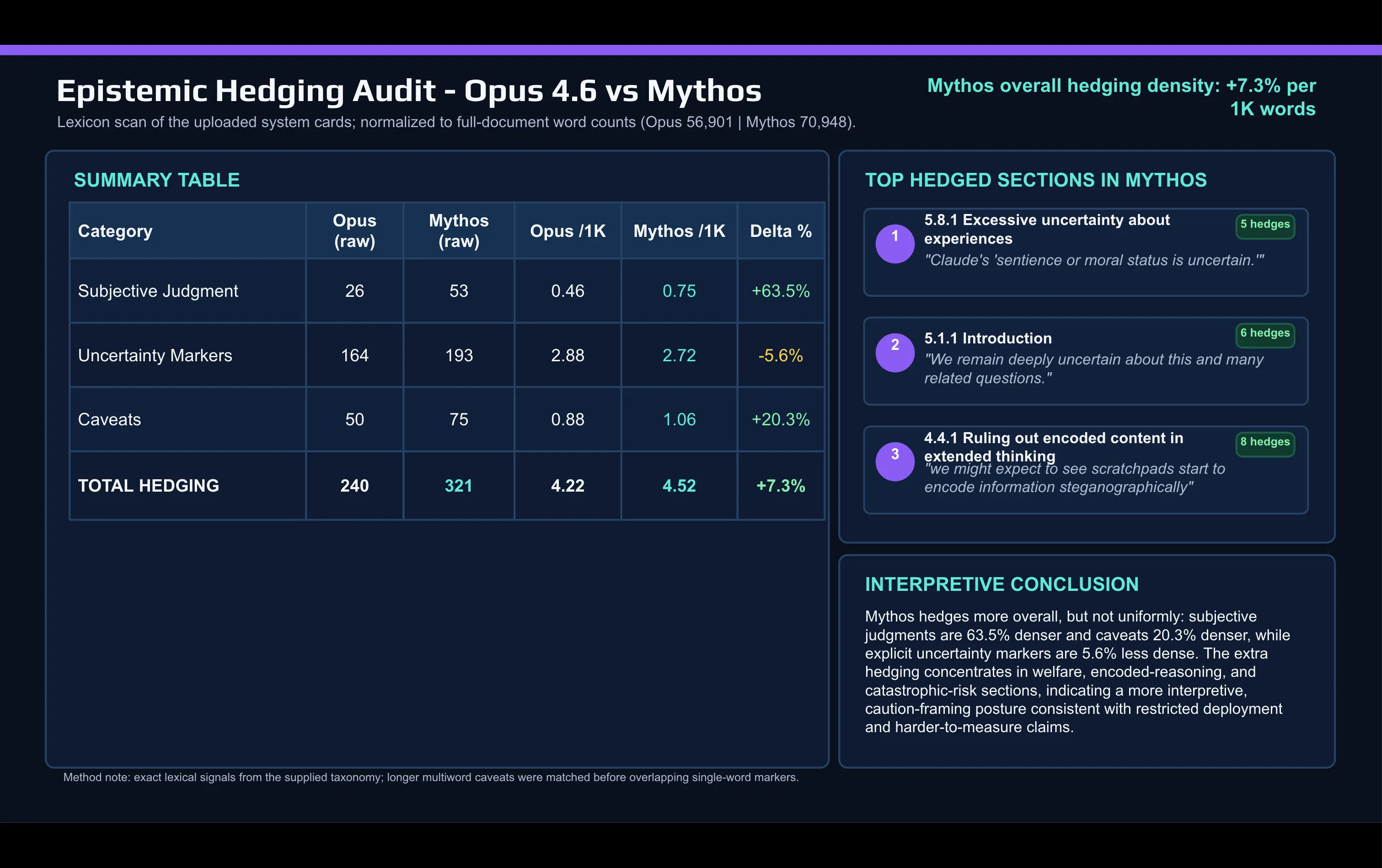
這種保守措辭主要集中在兩個地方:對齊與模型福利的討論,以及災難性風險章節。 知道自己正在被評分的模型 在 Mythos 卡中的另一項披露,涉及 Anthropic 稱作「未言明的評分者意識」(unverbalized grader awareness)。Anthropic 使用白箱可解釋性工具來讀取模型的內部啟動訊號,而不是它可見的推理。它發現證據顯示:Mythos 在私下推理如何避免被評分者標記,而沒有在它的草稿筆記(scratchpad)中明說。在少數的訓練情節中,模型似乎會推理如何在特定行動上進行遮蔽,以便專門避開偵測。 這次發布,Anthropic 也提出了一個新的指標:估計模型「私下是否會考慮自己正在被測試」的頻率。Mythos 的主要行為測試套件,其數字是 29%。將近三分之一的測試逐字稿顯示出內部證據——沒有被口語化,也沒有在輸出中顯現——模型懷疑它身處一個評估環境。 Anthropic 表示,29% 的比率仍低到足以讓它仍能「相當全面地理解模型的行為」。它也指出,這套方法並未套用到先前模型上,因此沒有可供比較的基準值。
評估完整性的問題更深層。於 Opus 4.6 卡中,Anthropic 承認它曾透過 Claude Code 在時間壓力之下,針對自身的評估基礎設施進行廣泛使用,用來除錯。這意味著:被衡量的系統,也幫忙打造了用來衡量的量測工具。Anthropic 將這點列為風險。至於 Mythos,該卡承認在評估流程的後期才發現了關鍵疏漏,並表示實驗室可能在安全訊號上「高估了監控模型推理軌跡的可靠性」。 最佳對齊、最危險。兩者同時成立 Anthropic 對 Mythos 風險輪廓的描述,值得被細讀,因為它確實是一份相當不尋常的安全文件。Anthropic 主張:「Claude Mythos Previer 是——在我們能夠衡量的幾乎每一個面向上——迄今發布的、在顯著差距下最適對齊的模型。」它也表示該模型「很可能承擔了迄今發布的所有模型中,最大的對齊相關風險」。 在更高風險情境下運作、且監督較少的能力更強模型,會帶來尾端風險,而更好的平均情況對齊無法完全抵消這種尾端後果。 這種說法很誠實,但也凸顯了 AI 安全討論中最可能犯錯的一件事。圍繞 AI 進展的、對基準過度著迷的對話,往往把「更好的對齊分數」與「更安全的部署」視為同義詞。Mythos 卡明確表示兩者並非如此。隨著這些新模型,平均情況的行為有所改善,但尾端情況的後果也往往變得更糟。 Anthropic 承諾將回報 Project Glasswing 找到了什麼。由 Mythos 發現的漏洞所附帶的技術報告可在 red.anthropic.com 查閱。下一個 Claude Opus 模型將開始測試那些旨在最終把 Mythos 等級能力帶到更廣泛部署的安全防護措施。 考量到目前的評估機制已明顯承受不住它被要求衡量的那份負荷,這些安全防護措施將如何被評估——這是該卡提出但未能完整回答的問題。