DeepSeek V4-Pro 以比 GPT-5.5 Pro 低 98% 的成本推出
DeepSeek 於 2026 年 4 月 24 日發布 DeepSeek-V4-Pro 與 DeepSeek-V4-Flash 的預覽版本;兩者都是具備一百萬 token 上下文視窗的開放權重模型,且定價顯著低於可比的西方替代方案。根據該公司官方規格說明,V4-Pro 模型的每一百萬輸入 token 價格為 1.74 美元、每一百萬輸出 token 價格為 3.48 美元——大約是 Claude Opus 4.7 價格的 1/20,且比 GPT-5.5 Pro 低 98%。
模型架構與規模
DeepSeek-V4-Pro 具有 1.6 兆(trillion)總參數,使其成為迄今 LLM 市場中最大的開源模型。不過,每次推論時僅有 490 億(billion)參數啟動,使用的是 DeepSeek 所稱的 Mixture-of-Experts(混合專家)方法,且自 V3 以來已進行精煉。此設計讓整個模型可保持休眠狀態,只有在任何特定請求中與之相關的切片才會被啟動;在降低運算成本的同時,仍能維持知識能力。
DeepSeek-V4-Flash 的規模更小,擁有 2840 億(billion)總參數與 130 億(billion)啟動參數。依據 DeepSeek 的基準測試,它「在給予更大的思考預算(thinking budget)時,達到與 Pro 版本相當的推理表現」。
兩款模型都將一百萬 tokens 的上下文支援作為標準功能——約 750,000 字,或是幾乎整套《魔戒》(Lord of the Rings)三部曲,再加上額外文本。
技術創新:大規模注意力機制
DeepSeek 透過在技術論文中提出兩種新的注意力類型,來解決長上下文處理所固有的計算擴展問題;該論文如公司在 GitHub 上提供的技術文件所述。
標準 AI 注意力機制面臨一個殘酷的擴展問題:每當上下文長度加倍時,計算成本大約會增加四倍。DeepSeek 的解決方案包含兩種互補的做法:
壓縮稀疏注意力(Compressed Sparse Attention) 以兩個步驟運作。首先,它會壓縮 token 群組——例如把每 4 個 tokens 壓成一個條目。接著,它不會對所有壓縮條目進行注意,而是使用「Lightning Indexer」去選擇針對任何給定查詢最相關的結果。這會把模型的注意力範圍,從一百萬 tokens 降到一個更小的、由重要片段構成的集合。
高度壓縮注意力(Heavily Compressed Attention) 採取更激進的策略,將每 128 個 tokens 折疊成一個條目,而不進行稀疏選擇。雖然這會失去細粒度細節,但它提供了極其低成本的全域視角。兩種注意力類型在交替層(alternating layers)中運行,使模型能同時維持細節與概覽。
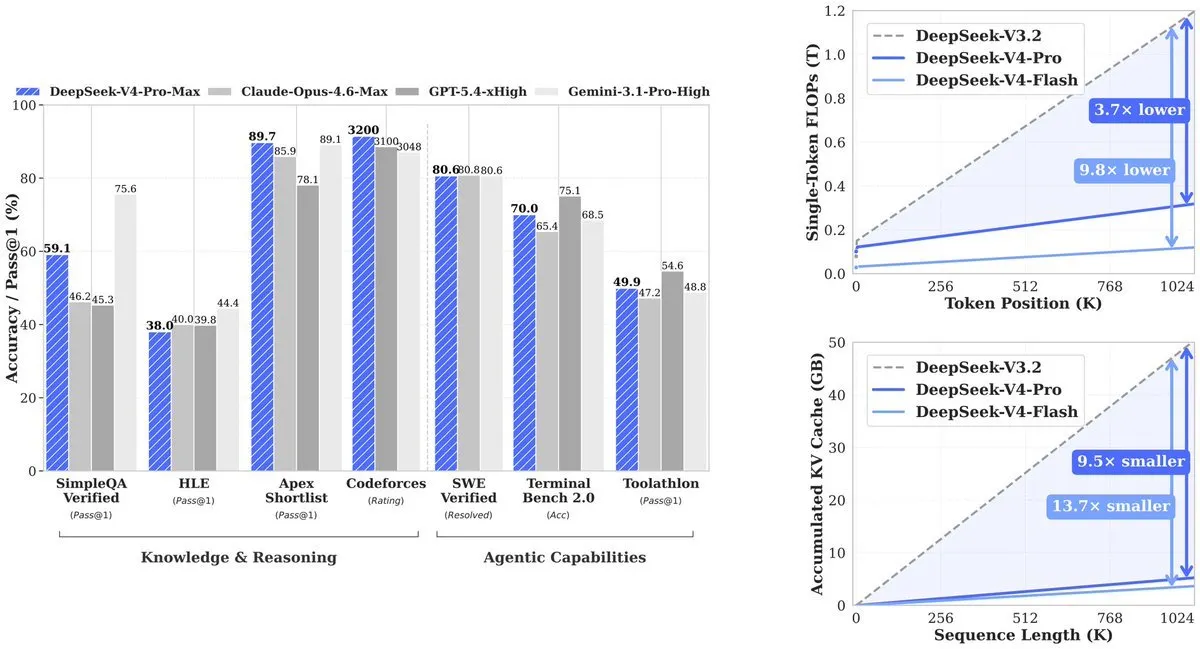
結果是:V4-Pro 使用了其前代 (V3.2) 所需運算量的 27%。KV cache——追蹤上下文所需的記憶體——下降到 V3.2 的 10%。V4-Flash 的效率進一步提升:相較於 V3.2,計算量為 10%、記憶體為 7%。
基準表現與競爭地位
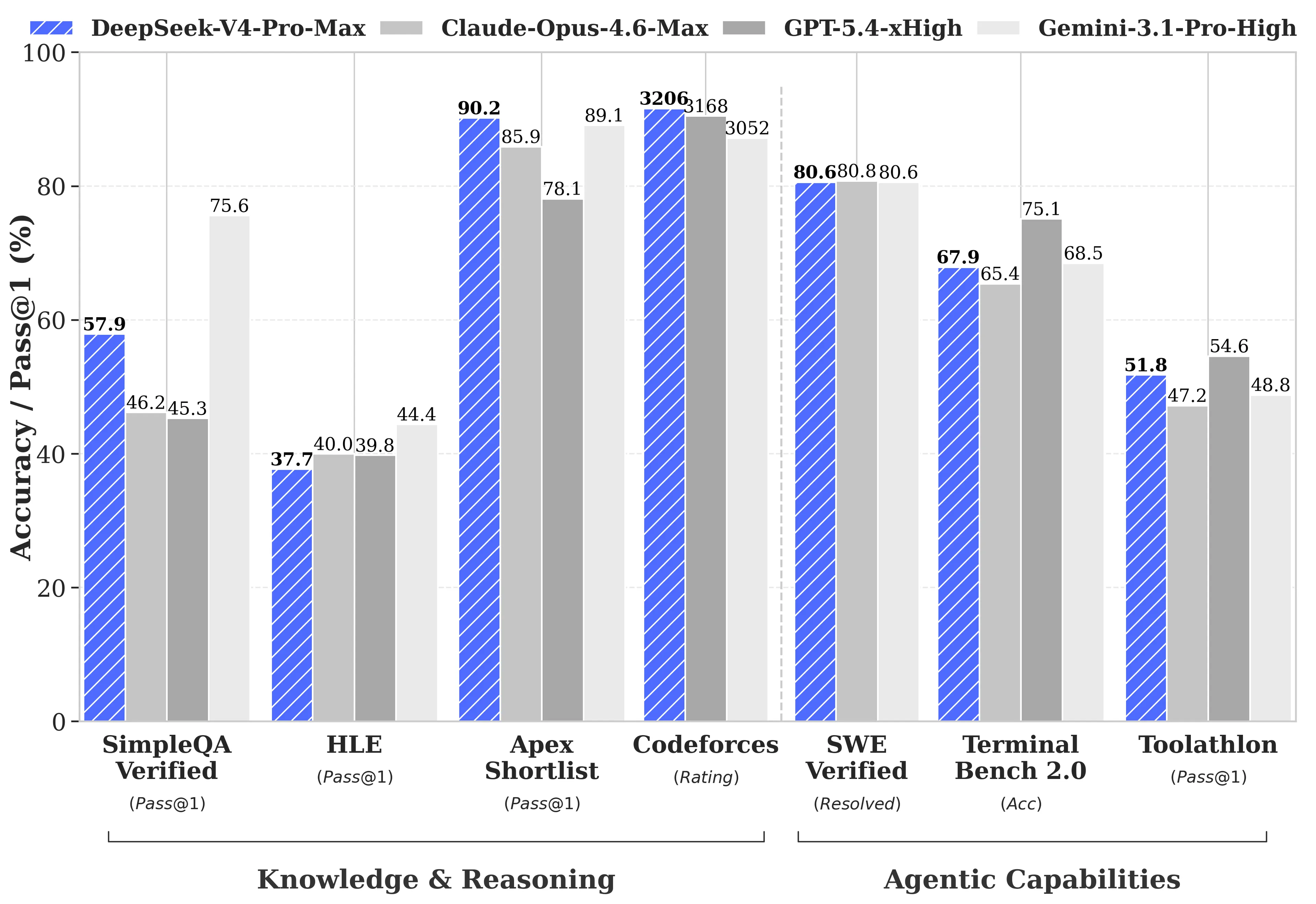
DeepSeek 發布了針對 GPT-5.4 與 Gemini-3.1-Pro 的完整基準測試對比,包括 V4-Pro 落後於競爭者的領域。在推理任務上,依據 DeepSeek 的技術報告,V4-Pro 的推理表現比 GPT-5.4 與 Gemini-3.1-Pro 落後約三到六個月。
在 V4-Pro 領先的地方:
- Codeforces (競賽程式設計):V4-Pro 成績為 3,206,約在所有實際人類參賽者中排名第 23
- Apex Shortlist (精選數學與 STEM 問題):通過率 90.2%,高於 Opus 4.6 的 85.9% 與 GPT-5.4 的 78.1%
- SWE-Verified (GitHub 問題解決):80.6%,與 Claude Opus 4.6 相同
在 V4-Pro 落後的地方:
- MMLU-Pro (多任務):Gemini-3.1-Pro 為 91.0%,而 V4-Pro 為 87.5%
- GPQA Diamond (專家知識):Gemini 為 94.3,V4-Pro 為 90.1
- Humanity's Last Exam (研究生級):Gemini-3.1-Pro 為 44.4%,V4-Pro 為 37.7%
在長上下文任務上,V4-Pro 領先開源模型,並在 CorpusQA (模擬真實文件分析於一百萬 tokens) 上擊敗 Gemini-3.1-Pro,但在 MRCR 落後於 Claude Opus 4.6;MRCR 衡量的是在長文本中深埋的特定資訊的檢索能力。
Agentic 與程式能力
V4-Pro 可以在 Claude Code、OpenCode 以及其他 AI 程式工具中運行。根據 DeepSeek 對 85 位使用 V4-Pro 作為主要程式代理(coding agent)的開發者所做的內部調查,52% 的受訪者表示它已準備好成為他們的預設模型,39% 傾向於「是」,且少於 9% 的受訪者表示「否」。DeepSeek 的內部測試顯示,V4-Pro 在 agentic 程式任務上優於 Claude Sonnet,並接近 Claude Opus 4.5。
Artificial Analysis 在 GDPval-AA 上將 V4-Pro 排名第一;GDPval-AA 是一個基準,用於測試具經濟價值的知識工作,涵蓋金融、法律與研究任務等領域。V4-Pro-Max 得分為 1,554 Elo,領先於 GLM-5.1 (1,535) 與 MiniMax 的 M2.7 (1,514)。Claude Opus 4.6 在同一基準上的得分為 1,619。
V4 引入「交錯式思考(interleaved thinking)」,能在工具呼叫(tool calls)之間保留完整的思考鏈(chain of thought)。在先前模型中,當代理進行多次工具呼叫——例如搜尋網路、執行程式,然後再次搜尋——模型的推理上下文會在各輪之間被清空。V4 則在步驟之間維持推理連續性,避免在複雜的自動化工作流程中造成上下文遺失。
競爭格局與定價背景
V4 的發布正值 AI 領域出現顯著動態。Anthropic 於 2026 年 4 月 16 日推出 Claude Opus 4.7。OpenAI 的 GPT-5.5 於 2026 年 4 月 23 日上線;其中 GPT-5.5 Pro 的定價為每 $30 百萬(per million)輸入 token $180 與每 (百萬(per million)輸出 token )。在 Terminal Bench 2.0 上,GPT-5.5 以 (82.7%) 對 70.0%$1 取得勝出;該測試評估複雜的命令列代理(command-line agent)工作流程。
Xiaomi 於 2026 年 4 月 22 日推出 MiMo V2.5 Pro,提供完整的多模態能力 $3 image, audio, video(,其定價為每 )百萬(per million)tokens 的 input and output。Tencent 則在 GPT-5.5 發布同一天釋出 Hy3。
從定價角度來看:Cline 執行長 Saoud Rizwan 指出,若 Uber 使用 DeepSeek 而不是 Claude,它在 2026 年的 AI 預算——據報導足以使用四個月——將可撐上七年。
![Pricing comparison and Uber budget analysis]https://img-cdn.gateio.im/social/moments-0ee5a4bf95-cbc5686e31-8b7abd-badf29
部署與供應情況
V4-Pro 與 V4-Flash 皆採用 MIT 授權,並可在 Hugging Face 上取得。就目前而言,這些模型僅支援文字;DeepSeek 表示它正在開發多模態能力。兩款模型都可在本地硬體上免費運行,或依公司需求進行客製化。
DeepSeek 既有的 deepseek-chat 與 deepseek-reasoner 端點已分別在非思考(non-thinking)與思考(thinking)模式下路由到 V4-Flash。舊版 deepseek-chat 與 deepseek-reasoner 端點將於 2026 年 7 月 24 日退役。
DeepSeek 訓練 V4 時部分使用了華為 Ascend 晶片,從而繞過美國出口限制。該公司表示,當 2026 年下半年新增的 950 個超級節點(supernodes)上線後,Pro 版本那已經偏低的價格還會進一步下調。
實際影響
對企業而言,這種定價結構可能會改變成本效益(cost-benefit)計算。以每一百萬輸入 token 1.74 美元的價格在開源基準上表現領先的模型,會讓大規模的文件處理、法務審查與程式碼生成管線,相較於六個月前變得顯著更便宜。一百萬 token 的上下文允許把整個程式碼庫或法規申報文件在單一請求中處理,而不是必須切分成多次呼叫。
對開發者與獨立創建者(solo builders)來說,V4-Flash 是主要考量。以每一百萬 tokens 的輸入 0.14 美元、輸出 0.28 美元計價,它比一年前被視為預算選項的模型更便宜,同時又能處理 Pro 版本所能完成的大多數任務。
相關新聞
DeepSeek 推出 V4 開源預覽版,技術評分 3206 超越 GPT-5.4
OpenAI 推 GPT-5.5:12M 脈絡、AA 指數登頂、Terminal-Bench 82.7% 改寫代理基準
Bittensor TAO 價格前景取決於 AI 網路成長
OpenAI 推 ChatGPT Workspace Agents:Codex 驅動、團隊共享、Slack 整合
Google Cloud Next 2026:推出 Gemini 企業代理平台,7.5 億美元助顧問落地