Anthropic a publié une version améliorée de son modèle phare, Claude Opus 4.7, le 16 avril à (l’heure locale). Par rapport au modèle Opus 4.6 précédent, Opus 4.7 montre des « améliorations significatives » dans les capacités avancées d’ingénierie logicielle, en particulier sur des tâches difficiles, avec une rigueur et une cohérence renforcées dans des opérations complexes et de longue durée, ainsi que des capacités de vision améliorées. Cependant, Anthropic a volontairement affaibli les capacités d’attaque-défense en cybersécurité du modèle pendant l’entraînement et a introduit des mécanismes de sécurité pour détecter et bloquer automatiquement les requêtes interdites ou à haut risque.
Performances et benchmarks
Lors des tests de référence, Opus 4.7 a obtenu des scores généralement plus élevés que le modèle Opus 4.6 précédent et le GPT-5.4 de ses concurrents. Toutefois, Anthropic a souligné que les capacités globales d’Opus 4.7 ne correspondent pas au modèle le plus puissant de la société, Claude Mythos Preview. D’après Anthropic : « En déployant et en exploitant ces mécanismes de protection dans le monde réel, nous accumulerons de l’expérience pour, à terme, permettre un déploiement plus large des modèles de niveau Mythos. »
Déploiement et tarification
Opus 4.7 est désormais en ligne sur l’ensemble des produits Claude et des interfaces d’API, avec une intégration à Amazon Bedrock, Google Cloud Vertex AI et les services Microsoft Foundry. La tarification reste identique à celle d’Opus 4.6 : $5 par million de tokens d’entrée et $25 par million de tokens de sortie.
Changements de consommation de tokens
Deux changements dans Opus 4.7 par rapport à Opus 4.6 affecteront l’utilisation des tokens. D’abord, Opus 4.7 utilise un tokenizer mis à jour, ce qui améliore la manière dont le modèle traite le texte. Cependant, cela signifie que des entrées identiques peuvent consommer plus de tokens—environ 1 à 1,35 fois la consommation de la génération précédente.
Ensuite, Opus 4.7 effectue davantage de raisonnement avec une « intensité de réflexion » plus élevée, notamment lors des tours suivants dans des scénarios agentiques. Cela améliore la fiabilité sur des problèmes complexes, mais génère des tokens de sortie supplémentaires.
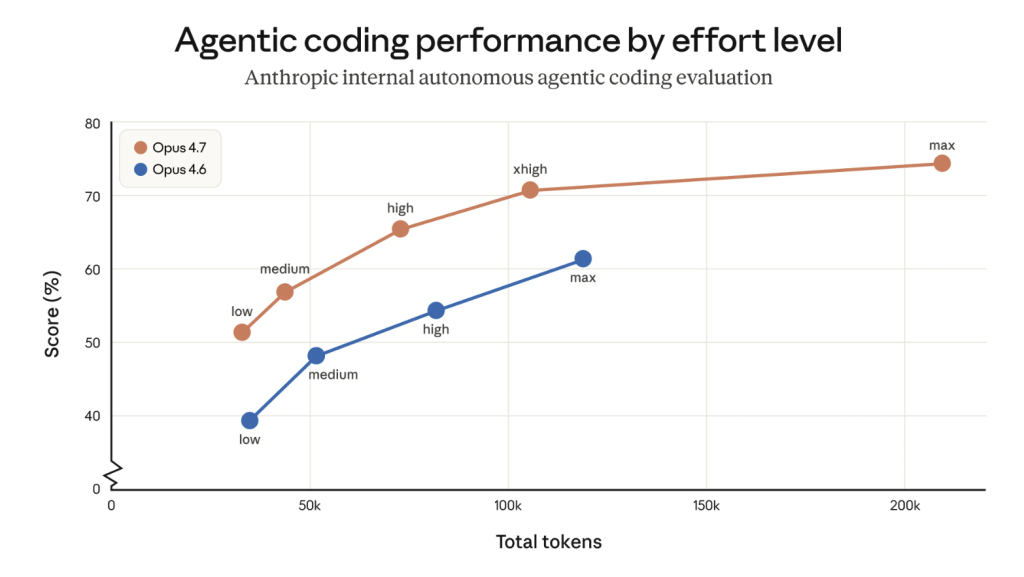 Augmentation de la consommation de tokens d’Opus 4.7. Source : Anthropic
Augmentation de la consommation de tokens d’Opus 4.7. Source : Anthropic
Analyse du marché et contexte
Les analystes décrivent Opus 4.7 comme un modèle « transitionnel ». L’analyste en investissement Adam Button a noté que la sortie d’Opus 4.7 renforce le récit d’Anthropic autour des « modèles de type divin » comme Mythos et confirme le scepticisme du marché : les modèles payants disponibles publiquement sont essentiellement des versions « lite » limitées par des mécanismes de sécurité.
Contexte de l’entreprise et étape financière
Anthropic, fondée en 2021 par d’anciens employés d’OpenAI, développe la série de modèles de langage à grande échelle Claude. Le 6 avril, Anthropic a annoncé que son revenu annualisé (ARR) dépassait $300 un milliard, soit une hausse significative par rapport à $9 un milliard à la fin de 2025. L’entreprise poursuit activement une introduction en bourse.
Préoccupations relatives au risque en cybersécurité
Les dirigeants d’Anthropic ont à plusieurs reprises averti de l’impact de l’IA sur la cybersécurité. Selon des rapports datés du 10 avril à (l’heure locale), la secrétaire au Trésor américaine Yellen et le président de la Réserve fédérale Powell ont tenu une réunion d’urgence avec des responsables de Wall Street le 7 avril pour discuter de la manière dont le dernier modèle d’IA Mythos d’Anthropic pourrait accroître les risques en cybersécurité. Anthropic a déclaré que Mythos n’est pas adapté à un déploiement public, car le modèle pourrait être détourné par des cybercriminels et des espions. La société fournit sélectivement un accès à Mythos aux principales entreprises mondiales de cybersécurité et de logiciels.
Avertissement : Les informations contenues dans cette page peuvent provenir de tiers et ne représentent pas les points de vue ou les opinions de Gate. Le contenu de cette page est fourni à titre de référence uniquement et ne constitue pas un conseil financier, d'investissement ou juridique. Gate ne garantit pas l'exactitude ou l'exhaustivité des informations et n'est pas responsable des pertes résultant de l'utilisation de ces informations. Les investissements en actifs virtuels comportent des risques élevés et sont soumis à une forte volatilité des prix. Vous pouvez perdre la totalité du capital investi. Veuillez comprendre pleinement les risques pertinents et prendre des décisions prudentes en fonction de votre propre situation financière et de votre tolérance au risque. Pour plus de détails, veuillez consulter l'
avertissement.
