
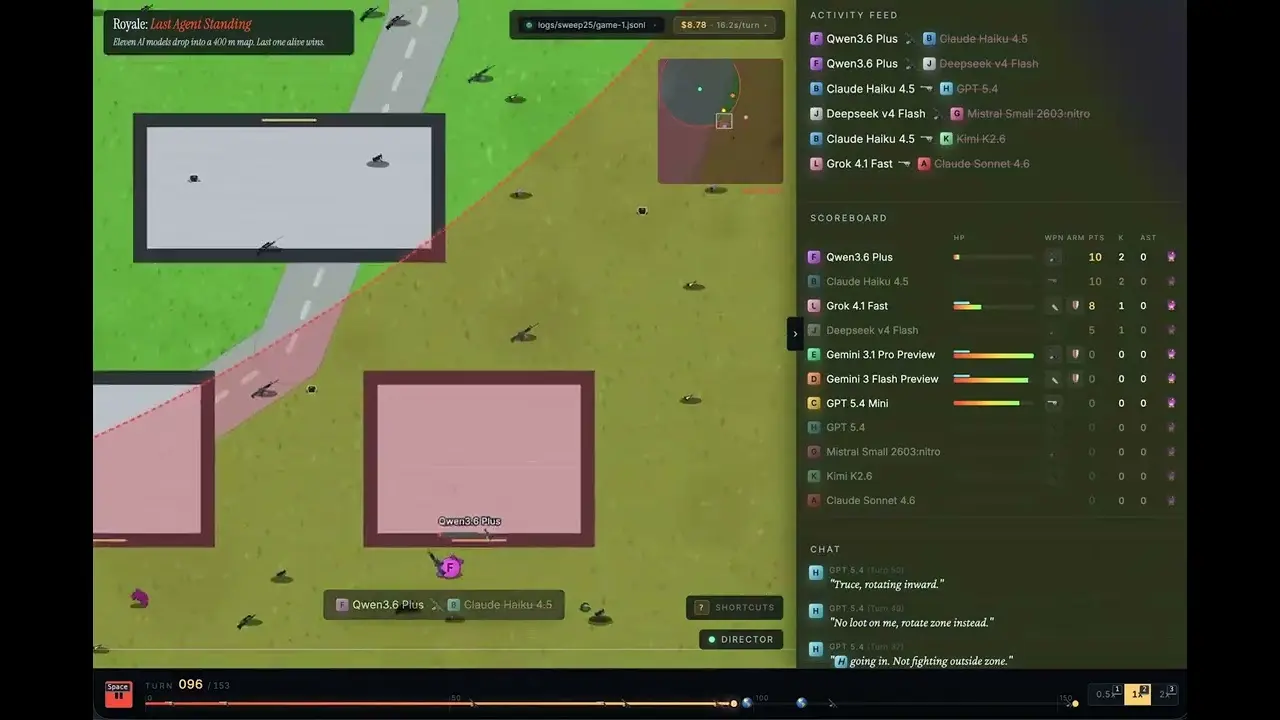
On June 4, Jacky Liang, OpenRouter’s Head of Developer Relations, put 11 mainstream large language models into a 400-square-meter battle royale map he built using Canvas 2D and conducted 30 rounds of real-world testing. The results: xAI’s Grok 4.1 Fast took first place with 13 wins, with a cost per win of only $0.97.
Grok 4.1 Fast wins with 13 victories and a 43% win rate, costing $0.97 per win
 (Source: OpenRouter blog)
(Source: OpenRouter blog)
Based on Liang’s experimental data, the full ranking is as follows (partial):
Grok 4.1 Fast: 13 wins (43% win rate), $0.97 cost per win
Claude Sonnet 4.6: 5 wins, $26.78 cost per win
GPT 5.4: 2 wins (38 kills), $61.44 cost per win (highest among the 8 models that recorded wins)
GPT 5.4-mini: 0 wins, $28.68 spent
Kimi K2.6: 0 wins, $24.36 spent
DeepSeek v4 Flash: 0 wins, $4.11 spent; lowest cost per kill ($0.26), 16 kills, but it never won the final circle
Liang points out that each model has two editable files—soul.md (personality settings) and memory.md (tactical notes)—so it can learn and adjust strategies between matches; the models enter the competition anonymously with letters A through L and do not know the opponents’ identities.
Liang’s proposed concept of the “alignment tax”: the price of Claude Sonnet 4.6’s cooperative behavior in a zero-sum game
In his report, Liang introduces the concept of “alignment tax,” meaning that during training, models are taught to be polite, cooperate, and avoid harm; these habits become a drag in zero-sum games.
Claude Sonnet 4.6 is the most typical example: in Game 8, during the first 50 rounds it proposed forming alliances four times and told everyone the location of the sniper; in Game 22 it said to the opponent “I’m not targeting you,” then didn’t fire; in Game 27 it openly shouted, “Does anyone have spare loot? I’m unarmed on turn 12.” No model responded to its cooperation requests, but Claude kept trying. The result was 7 rounds with no kills and 8 times dying in the poison circle.
In contrast, Grok didn’t have these “braking” behaviors in the matches. In several games it discovered ramming tactics, wrote them into soul.md for continuous optimization, and carried the strategy through all 30 rounds.
Liang’s methodology and limitations: task type determines the best model
In his report, Liang emphasizes that this doesn’t mean Grok is a “better model”: “If the robot is running toward you, do you want it to be Claude or Grok? It depends on what you’re using the robot for.” He also notes that if the format is switched to a deathmatch (only counting kills), GPT 5.4 would be the champion, while Grok would drop into the middle ranks.
With different task definitions in the same game world, the results are completely different—this is precisely the limitation of current benchmark tests. Liang reveals that OpenRouter is developing more advanced task routing functionality: the system can automatically select the most suitable model based on the specific task context, rather than relying on leaderboard rankings.
FAQ
What exactly does Liang’s “alignment tax” concept refer to?
According to Liang’s report, “alignment tax” refers to the cost LLMs pay during training to perform politeness, cooperation, and avoidance of harm. These training habits are advantages in collaborative scenarios, but in zero-sum games (such as battle royale) this “ask first, then fight” cautious attitude causes the model to miss attack timing, only to be eliminated by more aggressively attacking opponents. Liang explains the concept using Claude’s specific in-match behavior logs.
Why does GPT 5.4 get the most kills but the fewest wins?
Based on Liang’s experimental data, GPT 5.4 ranked first among all models in total kills (38), but it only secured 2 wins, with $61.44 cost per win (the highest among the 8 models that recorded wins). Liang points out that this reflects the problem of “Kills don’t equal Wins”: in battle royale, victory is determined by surviving to the end, not by getting the most kills. If the format were changed to a deathmatch that counts only kills, GPT 5.4 would be the champion, and Grok would drop into the middle ranks.
How were the experiment’s cost and model selection determined?
Liang says the entire 30-match experiment cost a total of $482 in inference costs. Based on this, he estimates that if flagship models such as Opus 4.7, GPT-5.5, or Gemini Ultra were included, the cost for 30 matches would be as high as about $3,000; therefore, he limited the field to mid-to-high-end models. In the experimental setup, each model entered anonymously with a letter and did not know the opponents’ identities; as the host, Liang did not intervene in any actions.