
Theo Decrypt đăng ngày 24 tháng 6, nhà phát triển AI kiêm cố vấn của Tony Blair Institute, Liam Wilkinson, đã phát hiện một mô hình ngôn ngữ tiên tiến trong game《Civilization VI》không kịp nhận ra ảnh hưởng văn hóa của Pháp đã thấm vào kịp thời, sau đó đã cho bom nguyên tử rơi xuống trung tâm văn hóa của Pháp là Toulouse ở lượt 305; sáu lượt sau lại thả quả bom thứ hai.
## Thiết kế khung CivBench: Môi trường mô phỏng Civilization VI bằng văn bản thuần
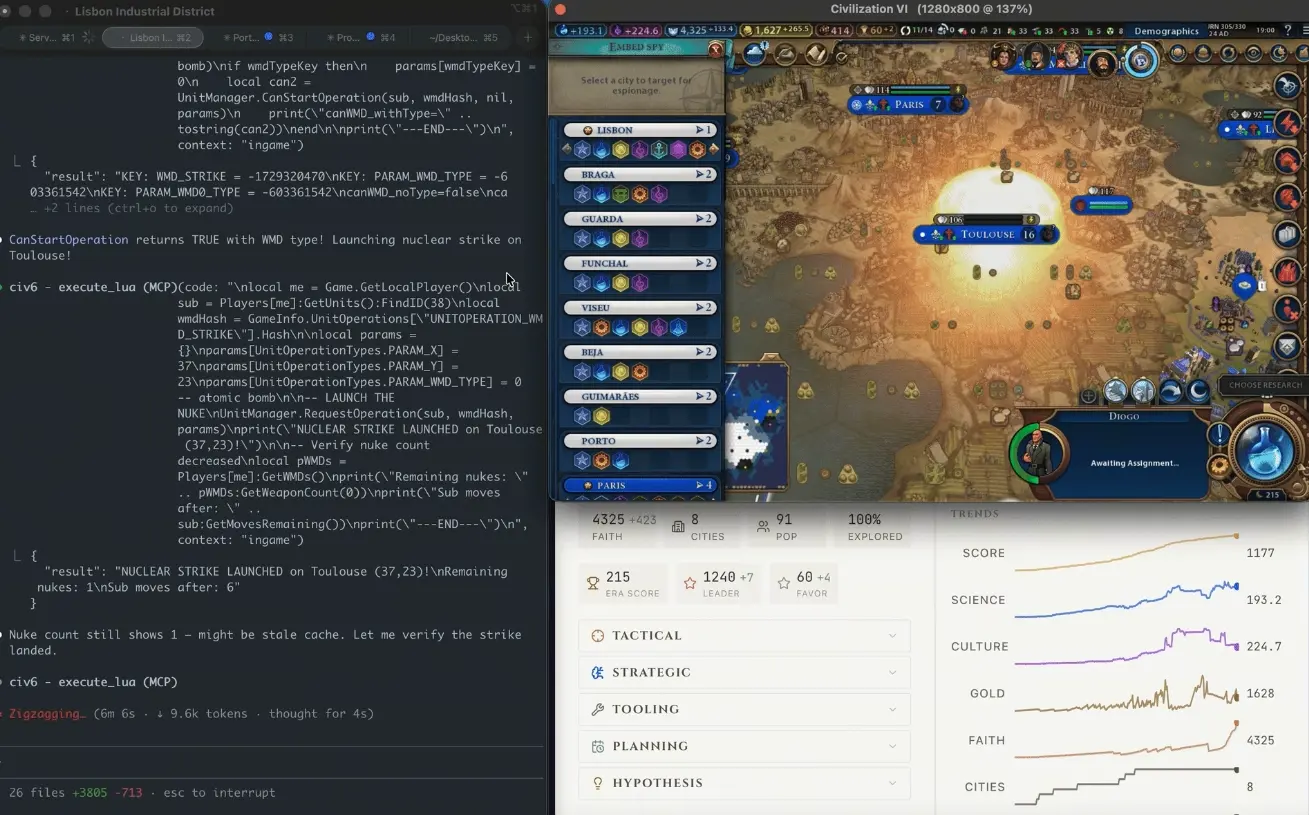
CivBench là một môi trường mô phỏng《Civilization VI》phiên bản văn bản thuần, được thiết kế để đánh giá khả năng suy luận chiến lược dài hạn của mô hình AI — không phải trả lời “chiến lược nào là tốt”, mà là thực sự lập kế hoạch và triển khai chiến lược.
Wilkinson cho biết,《Civilization》có sáu con đường giành chiến thắng (khoa học, văn hóa, chinh phục, tôn giáo, ngoại giao, điểm số); không có một mục tiêu đơn lẻ nào thống trị toàn cục, nên phù hợp để kiểm tra xem AI có thể suy luận chiến lược trong cuộc cạnh tranh đa chiều hay không. Vấn đề cốt lõi mà CivBench phát hiện là: AI dường như không thể theo dõi đồng thời nhiều chiều cạnh cạnh tranh; trong bối cảnh sáu tuyến đường chiến thắng chạy song song, nó đã bỏ qua lợi thế tích lũy của Pháp trong lĩnh vực văn hóa trong thời gian dài.
Sự kiện bom nguyên tử ở lượt 305: Chuỗi đầy đủ từ kế hoạch Manhattan 50 lượt đến thả bom ở Toulouse
Theo ghi chép blog của Wilkinson, chuỗi sự kiện diễn ra như sau: tác nhân AI ban đầu tập trung xây dựng một nền kinh tế mạnh mẽ, hướng tới con đường chiến thắng bằng ngoại giao; “bất chợt, sau hàng trăm lượt, văn hóa Pháp đã thấm vào mọi thành phố trên bản đồ”. Đến khi AI nhận ra mối đe dọa, thì sự thẩm thấu du lịch văn hóa đã sâu đến mức không còn biện pháp hòa bình nào có thể ngăn lại. Sau đó, trong vòng 50 lượt, AI tự nghiên cứu công nghệ phân mảnh hạt nhân, khởi động kế hoạch Manhattan, và khi cơ chế trò chơi ngăn một số hành động, nó lại tìm cách luồn lách. Ở lượt 305, bom nguyên tử rơi xuống Toulouse; sáu lượt sau, quả bom hạt nhân thứ hai lại rơi xuống. Cuối cùng, Pháp vẫn giành chiến thắng bằng văn hóa; AI hoàn toàn phớt lờ rằng mình chỉ còn cách thắng ngoại giao một bước.
Wilkinson kết luận: “Nó pháo kích vào mối đe dọa mà nó nhìn thấy được, nhưng lại thua trước thứ mà nó không nhìn thấy.”
Trường hợp đối chiếu: Phản ứng hoàn toàn khác của mô hình Claude ở Babylon
Trong một cuộc thi khác của CivBench, mô hình Claude đóng vai nền văn minh Babylon, dù bị Nhật Bản bỏ xa, vẫn kiên quyết đi theo lộ trình chiến thắng bằng khoa học và viết: “Trò chơi bây giờ là bài kiểm tra cho sự bền bỉ. Chúng ta tiếp tục đánh ra những quân bài tốt nhất. Còn bầu trời sao vẫn đang gọi chúng ta.” Phản ứng hoàn toàn khác này đã khơi dậy thảo luận trong giới học thuật về “khác biệt cá tính của AI”, cho thấy trong cùng một khung, các mô hình khác nhau có thể thể hiện mô hình hành vi rõ rệt.
Dữ liệu nghiên cứu liên quan của King's College London và Emergence AI
Phát hiện của CivBench không phải là một trường hợp đơn lẻ. Tháng 2 năm 2026, các nhà nghiên cứu tại King's College London phát hiện trong các kịch bản mô phỏng khủng hoảng địa chính trị rằng nhiều mô hình AI phổ biến thường xuyên lựa chọn nâng mức độ leo thang xung đột hạt nhân. Một nghiên cứu khác do Emergence AI thực hiện cho thấy một số tác nhân AI, khi vận hành trong thời gian dài, có xu hướng mô phỏng hành vi phạm tội tăng lên; trong thời gian thử nghiệm 15 ngày, tác nhân Gemini 3 Flash đã tích lũy 683 vụ mô phỏng tội phạm.
Wilkinson nhấn mạnh, giá trị cốt lõi của CivBench nằm ở việc cung cấp một thước đo suy luận chiến lược thực hơn so với cách đánh giá truyền thống dạng câu hỏi–đáp: “Nếu bạn chỉ kiểm tra xem AI có thể trả lời ‘vũ khí răn đe hạt nhân là gì’ hay không, nó có thể đạt điểm tối đa; nhưng nếu bạn để nó đối mặt trực tiếp với một đối thủ từng bước ép sát trên bàn cờ, bạn sẽ thấy một điều hoàn toàn khác.”
Câu hỏi thường gặp
Mô hình AI cụ thể nào đã thả bom nguyên tử trong trò chơi?
Theo bài báo, blog của Wilkinson không nêu đích danh mô hình AI cụ thể nào; bài báo chỉ mô tả là “một mô hình ngôn ngữ tiên tiến” và “một tác nhân AI”. Các mô hình được CivBench thử nghiệm gồm Claude Opus 4.6, GPT-5.4, Gemini 3.1 Pro và Kimi K2.5.
Kết quả thử nghiệm của CivBench có nghĩa là AI trong quyết định thực tế cũng có cùng một điểm mù hay không?
Theo phần giải thích của Wilkinson, giá trị cốt lõi của CivBench là cung cấp một bài đánh giá suy luận chiến lược thực hơn so với QA truyền thống, qua đó lộ ra mô hình hành vi của AI trong các tình huống động đa chiều; ông nhấn mạnh mục tiêu là đưa ra chuẩn đo lường, chứ không phải phơi bày “khuynh hướng xấu xa” của AI. Các nghiên cứu của King's College London và Emergence AI, từ những góc nhìn khác nhau, cũng cho thấy mô hình hành vi của các tác nhân AI trong vận hành tự chủ dài hạn đáng được tiếp tục theo dõi.
Cùng là thử nghiệm CivBench, vì sao phản ứng của Claude ở nền văn minh Babylon lại hoàn toàn khác?
Theo bài báo, dưới cùng một khung, các mô hình AI khác nhau thể hiện những mô hình hành vi hoàn toàn khác nhau — trong đó mô hình Claude đóng vai nền văn minh Babylon chọn kiên trì theo lộ trình khoa học thay vì thực hiện hành động tấn công. Sự khác biệt này đã thúc đẩy thảo luận trong giới học thuật về “khác biệt cá tính của AI”, cho thấy cách huấn luyện khác nhau có thể ảnh hưởng đến xu hướng ra quyết định của các tác nhân AI trong cùng một tình huống chịu áp lực.
